


BERT(バート)とは?自然言語処理モデルの仕組みや何ができるのかわかりやすく解説

自然言語処理の世界では革命的な技術として評価されているBERTは、私たちの日常生活でも意外と身近なところで活躍しています。
この記事では、BERTの基本概念から実際の活用例まで、専門知識がなくても理解できるよう解説します。
読み終えれば、AIが言葉を理解する仕組みの一端を知り、テクノロジーの進化をより身近に感じられるでしょう。
BERT(バート)とはGoogleに開発された自然言語処理モデルのこと

BERTとは「Bidirectional Encoder Representations from Transformers」の略称で、2018年にGoogleが発表した自然言語処理モデルです。日本語では「トランスフォーマーによる双方向エンコード表現」と訳されます。このモデルは、文の前後を同時に参照しながら処理する「双方向性」を持つ点が特徴であり、従来の片方向型モデルに比べて、より高度な文脈理解を実現しています。
GoogleがBERTを開発した背景には、検索クエリの多様化やVUI(Voice User Interface)の普及に伴う自然言語処理の高度化が求められたことが挙げられます。たとえば「ブラジル人はアメリカに行くのにビザが必要か?」といった複雑な命令文も、BERTの導入により正しく解釈され、ユーザーが本当に求める情報に到達しやすくなりました。
BERTはすでに多くの自然言語処理タスク、たとえば質問応答や感情分析、機械翻訳、文章分類などで活用されており、高い精度と汎用性を評価されています。学習済みモデルはオープンソースで公開されているため、企業や研究機関にとどまらず、一般の開発者でも活用できるのが魅力です。
自然言語処理モデルの基本的な仕組み
自然言語処理モデルとは、人間の言語である「自然言語」をコンピュータが理解・処理するために設計されたアルゴリズムのことです。日常的に使われる言葉は曖昧さや多義性を含んでおり、そのままではコンピュータには理解できません。そこで、言語を数値データに変換し、機械学習の枠組みで意味を処理できるようにするのが、自然言語処理モデルの目的です。
この仕組みでは、まず入力される文章に対して、前処理として「トークン化」や「正規化」などの処理を行い、次にそれをベクトル形式に変換します。このベクトル化された情報を、BERTのような深層学習モデルが読み取り、パターンや関係性を学習していきます。
たとえば、ある単語の意味を理解するには、その単語が文中でどのような位置にあるか、周囲にどんな単語があるか、といった文脈情報を考慮する必要があります。BERTは、Transformerという構造を使ってこの「文脈のつながり」を双方向から読み解くことができるため、従来モデルでは難しかった高精度な文理解が可能になったのです。
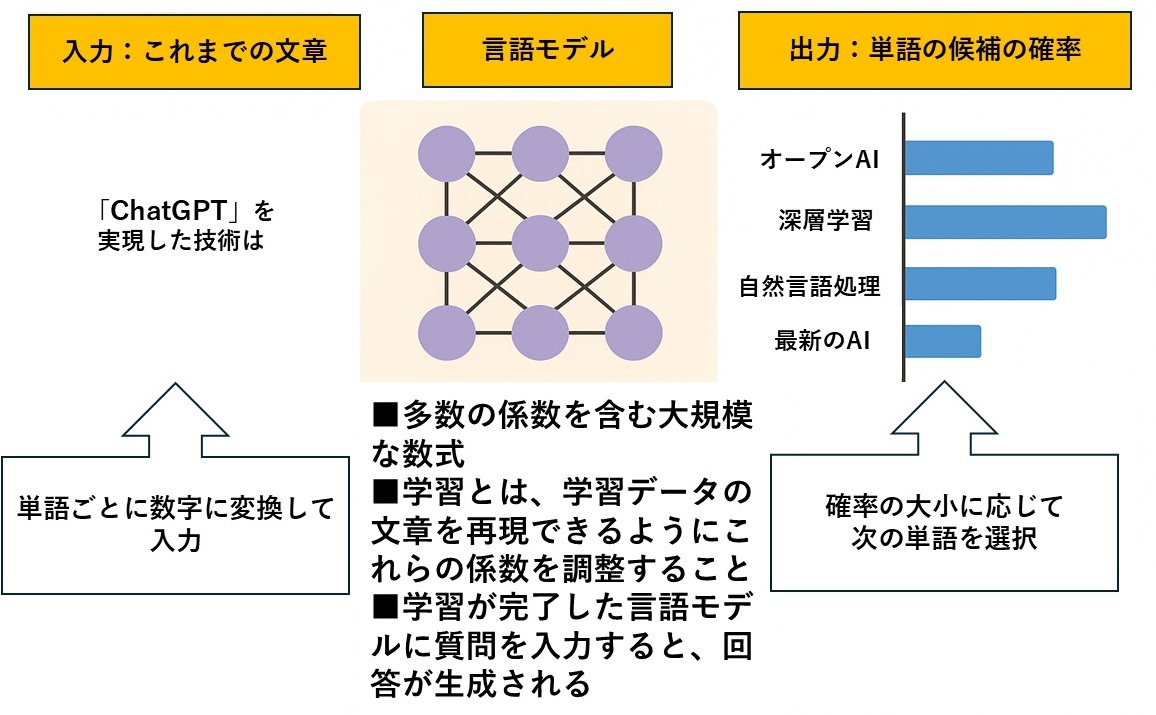
1.テキストの前処理
自然言語処理モデルにテキストを入力する前には、さまざまな前処理が行われます。これらの処理は、入力される文章をモデルが理解しやすい形に整える重要なステップです。BERTをはじめとする多くのモデルでは、この前処理の質が精度に大きく影響します。
まず行われるのがテキストのクリーニングです。これは、不要な記号や重複した空白などの除去、表記揺れの統一などを指します。たとえば、全角と半角、大文字と小文字の統一、HTMLタグや特殊文字の削除などがここに含まれます。
次に、トークン化(Tokenization)という処理が行われます。これは文章を単語や文節などの単位に分割する作業です。日本語のように単語の区切りが明示されていない言語では、とくに精度の高い形態素解析が求められます。BERTではSentencePieceやByte Pair Encodingといった手法が活用され、未知語を細かく分割して処理することで対応力を高めています。
最後に、単語の正規化が行われます。これは「走った」「走る」「走っている」など形が異なる語を統一する作業です。表記ゆれを正規化することで、モデルが単語の意味を一貫して学習できるようになります。
これらの前処理により、複雑で曖昧な自然言語のデータが、モデルにとって扱いやすい形式へと変換されるのです。
2.テキストのベクトル化
前処理を終えたテキストデータは、そのままではコンピュータには扱えません。自然言語処理モデルでは、文字列を数値化して初めて演算が可能になります。この数値化の工程を「テキストのベクトル化」と呼びます。
ベクトル化とは、単語や文の意味を多次元の数値として表現することです。たとえば「猫」という単語は、ある特定の数値列(ベクトル)に変換されます。BERTでは、こうしたベクトルに単語の意味や文脈情報を含めることで、モデルが文章の意味をより深く理解できるように設計されています。
従来の手法では、単語ごとに固定のベクトルを割り当てていましたが、BERTではその文脈に応じてベクトルが動的に変化します。たとえば「銀行」という単語も、「お金を預ける場所」と「川の土手」といった意味の違いを文脈から判断し、それに応じたベクトルを生成します。
このようにして、言葉を数値情報としてモデルに渡すことで、自然言語処理が可能になるのです。
3.機械学習モデルによる処理
ベクトル化されたテキストデータは、いよいよ機械学習モデルに入力されます。BERTのようなモデルは、この数値情報をもとにパターンを学習し、さまざまなタスクを実行します。自然言語処理の代表的なタスクには、以下のようなものがあります。
- 文章分類:入力された文章がどのカテゴリに属するかを判断する処理です。たとえば「これは映画のレビューですか、それともニュース記事ですか?」という問いに答えるために使われます。
- 感情分析:文章の中にある感情を解析するタスクです。ユーザーの投稿がポジティブなのかネガティブなのかを判断するなど、SNS分析やカスタマーサポートにも応用されています。
- 質問応答:ある文章を読んだ上で、与えられた質問に対して適切な答えを生成します。チャットボットや検索エンジンの高度な機能に使われる技術です。
- 機械翻訳:ある言語で書かれた文章を、別の言語に翻訳する処理です。BERTは翻訳精度の向上にも大きく貢献しています。
BERTは、Transformerという構造をベースに、これらのタスクを高精度でこなすことができます。また、BERT自体はあらかじめ大量のテキストから学習されており、少ないデータでも再学習(ファインチューニング)によって高精度な処理が可能です。
BERTの仕組みと特徴

従来の自然言語処理モデルは、単語ごとに固定のベクトルを割り当てていました。たとえば、「bank」という単語は、文の中で「銀行」を指す場合も「川の土手」を指す場合も、同じベクトルとして扱われていたのです。このような仕組みでは、文脈に応じた意味の違いを捉えることが難しく、文章全体の理解には限界がありました。
この課題を大きく乗り越えたのが、Googleが2018年に発表したBERT(Bidirectional Encoder Representations from Transformers)です。BERTは、Transformerという構造をもとに、文中の単語がどのような関係性で並んでいるのかを学習し、その文脈ごとに意味を理解できる点が革新的です。
たとえば「彼はbankに行った」という文では、「銀行」と解釈すべきですが、「彼は川のbankに座っていた」では「土手」となるべきです。BERTは前後の文脈を同時に参照することで、こうした意味の違いを正しく捉えることができます。
この文脈理解能力の高さから、BERTはGoogleの検索エンジンにも導入され、検索クエリの意図をより正確に理解できるようになりました。とくに、複雑で口語的な検索文でも、より適切な結果を返せるようになった点は、BERTの実用面での大きな成果といえます。
出典:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT最大の特徴「双方向性」とは?
BERTが持つ最大の強みは、「双方向性」にあります。従来のモデルであるLSTMやRNNでは、文章を左から右、あるいは右から左のいずれか一方向にしか読み取ることができませんでした。これでは、文の後半に登場する重要な単語が意味に影響を及ぼす場合に、うまく対応できないという課題がありました。
BERTはTransformerの構造を活用することで、前後両方の文脈を同時に読み取る「双方向エンコーディング」を実現しました。この仕組みによって、文中の単語の意味を、その前後関係を含めて正確に理解できるようになったのです。
たとえば「He sat on the bank and watched the river flow.」という文では、「bank」は「土手」と訳すのが自然です。一方で、「She went to the bank to withdraw money.」では「銀行」となります。BERTは前後の単語すべてを参考にしたうえで、「bank」の意味を正確に判断します。
この双方向性による文脈理解の向上は、従来の自然言語処理モデルでは不可能だった高精度な解析を可能にし、多くの自然言語処理タスクで大きな成果をもたらしています。
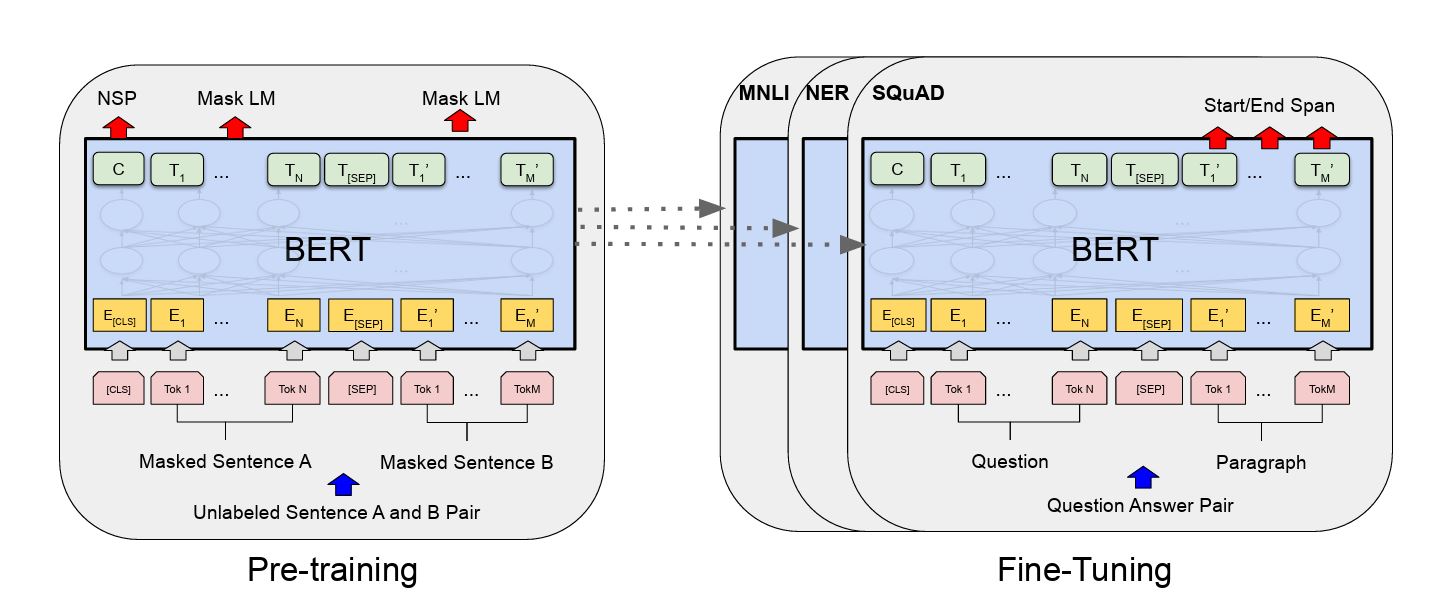
事前学習
BERTは「事前学習(Pre-training)」と呼ばれるステップを通じて、大量の自然文から言語のパターンや文脈的特徴を学習します。これは、特定のタスクに使う前に、モデルに一般的な言語知識を身につけさせる工程です。
事前学習には主に2つのタスクが用いられます。ひとつは「Masked Language Model(マスク付き言語モデル)」で、入力文の一部の単語を[MASK]に置き換え、その文脈から元の単語を予測するというものです。もうひとつは「Next Sentence Prediction(次文予測)」で、2つの文が連続するかどうかを判定することで、文と文の関係性を学習します。
これらのタスクによって、BERTは言葉の意味や文章の構造を広く理解できるようになります。しかも、この学習にはラベル付きのデータが不要で、インターネット上にある大量のテキストをそのまま使える点も、大きな利点とされています。
ファインチューニング
事前学習によって汎用的な言語知識を習得したBERTは、「ファインチューニング(Fine-tuning)」によって、特定のタスクに対応する形へと最適化されます。
この工程では、比較的少量のラベル付きデータを使い、BERTの上にタスクごとの出力層を追加して学習を行います。たとえば、感情分析であれば「ポジティブ/ネガティブ」の分類ラベルを使い、文章分類であれば各カテゴリに対応するラベルを用いて、タスクに特化した学習を行うという仕組みです。
ファインチューニングでは、事前学習で得られたパラメータを初期値として使いながら、新たにタスクに必要なパラメータを更新するため、少ないデータでも高精度なモデルが実現できます。これはBERTの汎用性の高さと応用のしやすさを支える重要な要素のひとつです。
BERTでできること|活用事例

BERTは、その優れた文脈理解能力を活かし、さまざまな自然言語処理タスクで活用されています。検索エンジンの高度化から、カスタマーサポートの自動化、SNS分析、翻訳精度の向上に至るまで、私たちの生活の中でBERTはすでに身近な存在となっています。
以下では、BERTが実際にどのような場面で利用されているのか、具体的な活用例を交えて紹介します。
検索エンジンの改善
BERTの代表的な活用例として、Google検索における検索精度の向上が挙げられます。従来の検索エンジンは、検索クエリの中のキーワードを中心に結果を返していました。しかし、複雑なクエリや口語的な表現では、ユーザーの意図を正しく解釈できず、関連性の低い結果が表示されることが課題でした。
BERTが導入されたことで、検索クエリの意味を文脈ごと理解し、文章全体から「何を知りたいのか」を判断できるようになりました。たとえば、「ブラジルからアメリカに旅行する人はビザが必要か?」という検索では、BERTが「to(〜へ)」の意味を正確に解釈し、旅行者の出発地と目的地の文脈を把握した上で、適切なビザ情報を表示できるようになっています。
質疑応答(QA)システム
BERTは、文章内の情報から質問に対する最適な答えを抽出する「QA(Question Answering)システム」においても高く評価されています。従来のシステムでは、文章と質問のキーワードの一致だけに頼っていたため、答えが見つからないことも多くありました。
一方、BERTは文脈を理解したうえで、質問に最も関連する部分を文章中から正確に抜き出すことができます。たとえば、製品のFAQシステムでは、「保証期間はどのくらいですか?」という質問に対して、マニュアル内の「購入日から1年間有効です」といった記述を的確に見つけて提示します。こうした精度の高さから、チャットボットやサポートツールにおけるBERTの採用が進んでいます。
文章の分類(テキスト分類)
テキスト分類は、与えられた文章がどのカテゴリに属するかを判断するタスクです。BERTはその高い精度により、スパムメールの判定やレビューの感情分析といった分野で広く利用されています。
たとえば、Eメールの振り分けにおいては、BERTが「これは迷惑メールかどうか」を文面の内容やトーンから判断します。さらに、SNS上の投稿分析では、「この投稿はポジティブかネガティブか」といった感情の分類にも使われており、企業のマーケティング活動や炎上リスクのモニタリングにも活用されています。
固有表現抽出
固有表現抽出とは、文章中に登場する「人名」「地名」「組織名」などの固有名詞を識別し、分類するタスクです。BERTは文脈を理解することで、前後の情報から単語の意味を把握し、単なる文字列の一致ではなく、意味に基づいた高精度な識別が可能となっています。
たとえば、「Appleは新製品を発表した」という文では、「Apple」が果物ではなく企業名であることを認識し、組織名として抽出します。また、医療や法律文書の処理においても、専門用語や固有名を正確に抽出できる点が評価され、専門分野向けのBERT(例:BioBERTやLegalBERT)も登場しています。
言語間翻訳
BERTは本来、翻訳タスクを主目的に設計されたわけではありませんが、「Multilingual BERT(mBERT)」という多言語対応モデルの登場により、異なる言語間での自然言語処理にも対応可能となっています。
このモデルでは、英語、日本語、スペイン語、アラビア語など、100以上の言語を同時に学習しており、文の意味や構造を共通の表現で捉えることができます。たとえば、日本語の質問文に対して、英語の資料から回答を抽出するようなクロスリンガルQAも実現可能になっています。これにより、国際的な情報検索や自動翻訳の精度向上に貢献しています。
感情分析
BERTは、感情分析の分野でも高い精度を発揮しています。感情分析とは、テキストデータに含まれる書き手の感情を判定するタスクで、「ポジティブ」「ネガティブ」「ニュートラル」といった分類が一般的です。SNSの投稿、商品レビュー、アンケートの自由記述欄など、感情のこもった文章が対象になります。
従来の分析手法では、キーワードベースで「うれしい」「嫌い」などの感情語をカウントして分類していましたが、文脈の違いや皮肉を正しく判断できないという課題がありました。たとえば、「最高だね、このサービス(怒)」のような投稿は、感情語としてはポジティブに見えますが、実際には不満を含んでいます。
BERTは双方向に文脈を読み取ることで、単語だけでなく、言い回しや文章構造から感情を理解できます。たとえば、ある製品レビューで「見た目は気に入っていたが、すぐに壊れてしまった」と書かれている場合でも、文全体を通じてネガティブな評価であると判断することができます。
BERTとGPT/ChatGPTとの違い

自然言語処理(NLP)の分野では、BERT以外にも数多くの強力な言語モデルが存在します。なかでもGPT(Generative Pre-trained Transformer)と、それを基にしたChatGPTは、文章生成能力において大きな注目を集めています。
本節では、BERTとGPT/ChatGPTの違いをわかりやすく整理し、それぞれの特徴を明確に比較します。
目的の違い:理解 vs 生成
BERTの主な用途は、自然言語の理解(NLU:Natural Language Understanding)です。たとえば、質問に対して文中から適切な答えを抜き出す、文書のカテゴリを分類する、といった「読み取る力」に特化しています。
一方でGPTは、自然言語の生成(NLG:Natural Language Generation)を目的としたモデルです。与えられたテキストの続きを書く、要約を作成する、質問に自然な文で回答するといった「文章を生み出す力」に優れています。
文脈の読み方の違い:双方向 vs 一方向
BERTは、文の前後両方の文脈を同時に読む「双方向型」のモデルです。これにより、単語の前後関係から意味をより正確に判断することができます。
一方、GPTは左から右に向かってテキストを読み、次に出てくる単語を予測する「一方向型」のモデルです。これは、人間が文章を書くプロセスに近く、自然な流れでの文章生成を得意としています。
ChatGPTとは?
ChatGPTは、GPTをベースにして会話形式に特化させたモデルです。ユーザーの入力に対して自然な返答を生成するように調整されており、カスタマーサポート、チャットボット、ライティング支援など幅広い用途で活用されています。
【BERTとGPT/ChatGPTの比較表】
| 特徴 | BERT | GPT / ChatGPT |
|---|---|---|
| 主な目的 | 自然言語理解 (NLU) | 自然言語生成 (NLG)、対話 |
| 構造 | Transformerのエンコーダーが中心 | Transformerのデコーダーが中心 |
| 文脈理解 | 双方向 | 主に一方向(左から右) |
| 得意なタスク | 文章分類、固有表現抽出、質問応答など | 文章生成、対話、要約、翻訳など |
| 代表例 | BERT、RoBERTa、ALBERT | GPT-3、GPT-4、ChatGPT |
BERTアップデートのGoogle検索への影響

2019年10月、Googleは検索アルゴリズムに対して「BERTアップデート」と呼ばれる大規模な変更を導入しました。これは、Googleの検索エンジンにBERT(Bidirectional Encoder Representations from Transformers)を組み込むことで、検索クエリの文脈をより深く理解できるようにする革新的なアップデートでした。
従来の検索では、入力された語句のキーワード一致が重視され、言い回しや語順の違いに十分対応できないことがありました。しかし、BERTの導入によって、検索エンジンは文全体の構造や意図を理解し、より関連性の高い検索結果を返すことが可能になりました。
たとえば「ブラジルからアメリカへ旅行する人はビザが必要か?」というような複雑な検索文でも、BERTによって出発地と目的地の文脈を正しく読み取り、ユーザーの意図に沿った情報が優先表示されるようになっています。
このアップデートにより、ユーザーはより自然な文章で検索しても、的確な情報にたどり着けるようになりました。一方で、SEOの観点では、「キーワードの最適化」だけに頼る手法の限界が明らかとなり、検索アルゴリズムに評価されるには、ユーザーにとって本当に役立つ質の高いコンテンツを提供することがより重要視されるようになっています。
BERTをさらに学びたい場合は?

BERTの構造や活用方法に関心を持った方のために、ここではさらに理解を深めるための情報源や、実際にモデルを使ってみたい方向けの入門的なヒントを紹介します。
BERTの論文と関連情報
BERTの原点となるのは、Googleの研究チームによって2018年に発表された論文「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」です。
この論文では、BERTの構造や学習方法、自然言語理解における革新性が詳細に説明されています。英語での記述ですが、論文解説記事や日本語訳を提供している技術ブログも多数あり、比較的取り組みやすい内容となっています。
また、BERTをもとに改良されたモデルも次々に登場しています。たとえば、以下のような派生モデルが有名です。
- RoBERTa:学習手法の最適化により、BERTを上回る性能を実現
- ALBERT:パラメータを圧縮して軽量化したモデル
- ELECTRA:マスク予測ではなく、生成と識別の訓練方式を採用
これらは、BERTの技術をさらに発展させた応用例として、研究や実務の両面で活用が進んでいます。
BERTの使い方【簡略版】
実際にBERTを使って自然言語処理タスクを試してみたい方には、Python言語とHugging Face社が提供するTransformersライブラリの利用がもっとも手軽な方法です。
このライブラリでは、事前学習済みのBERTモデルを数行のコードで読み込み、テキスト分類や質問応答といったタスクにすぐ応用できます。たとえば、以下のような流れで利用が可能です。
- データ準備:CSVやJSON形式などでテキストとラベルを整える
- モデル読み込み:TransformersのAutoModelForSequenceClassificationなどを使用
- ファインチューニング:学習済みのBERTに対し、手持ちのデータで再学習
- 評価・予測:モデルの精度を検証し、新しい入力に対して推論を行う
たとえば、ポジティブ/ネガティブを分類するような感情分析であれば、わずか数十行のコードでBERTを動かすことができます。実装の詳細に踏み込みすぎず、概念的な枠組みを理解するだけでも、自然言語処理の全体像がつかめるでしょう。
まとめ
BERTは自然言語処理の革新的技術として、ビジネスや学術分野で大きな可能性を秘めています。Googleが開発したこの双方向エンコーダーモデルは、文脈を理解する能力に優れ、検索エンジンの精度向上から感情分析まで幅広い活用が可能です。
BERTの仕組みを理解することで、AIを活用した言語処理の可能性を広げ、より高度なコミュニケーションシステムの構築に貢献できるでしょう。今後も発展し続けるこの技術を学び、活用することで、デジタル時代のコミュニケーションをより豊かなものにできます。
- SEO対策でビジネスを加速させる

-
SEO対策でこんな思い込みしていませんか?
- 大きいキーワードボリュームが取れないと売上が上がらない・・
- コンサルに頼んでもなかなか改善しない
- SEOはコンテンツさえ良ければ上がる
大事なのは自社にあったビジネス設計です。
御社の課題解決に直結するSEO施策をご提案します
- プロフィール
-

-
GMO TECH株式会社



- 2012年より一貫して検索エンジン領域のコンサルティング業務に従事。 2017年にGMO TECH社に参画。営業組織の構築、新商材開発、マーケティング部門立ち上げをおこなう。 現在、MEOコンサルティング、SEOコンサルティング、運用型広告などSEM領域全体を統括し、 お客様の期待を超える価値提供を行うため日々、組織運営・グロースに奔走している。
-
GMO TECH株式会社
 シェア
シェア




