


googleクローラーとは?種類やseoで活用する方法を解説

この記事では、Googleクローラーの役割や代表的な種類、SEOで活用する具体的な方法を解説していくので、ぜひ参考にしてください。
Googleクローラーとは
Googleクローラーとは、Googleが採用したWebサイトを検索エンジンにインデックスするためのWebページ収集プログラムのことです。
Googleクローラーは主にWebサイトを巡回して、内部リンクと外部リンクで繋がっているWebサイトの情報をgoogleのデータベースに保存していく役割があります。登録された情報はGoogleのさまざまなアルゴリズムを元にページをランク付けされ、ランキング形式で検索結果に表示されるのが特徴です。
Googleクローラーには、スマホ用・PC用・CSS用・画像用など、取得する情報に応じた複数の種類が存在します。
Googleクローラーの代表的な種類
Googleクローラーは、スマートフォンが主流になってきたことや検索方法の機能増加により、複数種類のクローラーでWebサイトの情報を収集しています。なかでも代表的なものが、パソコン検索に対応するパソコン用botと、スマートフォンからの検索に対応するスマホ用botです。
パソコンから検索することを前提として評価されているWebサイトと、PCよりも処理速度が遅いスマートフォンに表示するために最適なWebサイトは必ずしも一緒ではないため、クローラーが分かれています。パソコン用とスマホ用のgooglebotは、robot.txtファイルでクロールを制限することも可能です。
Googleクローラーはほかにも、画像用botや動画用bot、ニュース用botなど、ユーザーが検索した際に最適な情報を表示するためさまざまな種類があります。
スマートフォン用 Googlebot
スマートフォン用のGoogleクローラーである「Googlebot-Mobile」は、スマートフォン向けのWebサイトにおいて情報を収集する役割を持つクローラーです。スマートフォンから検索した際、レイアウトや表示速度など、スマートフォンで快適に閲覧できるモバイルフレンドリーに対応したWebサイトをランキング付けして検索結果に表示します。
スマートフォン用Googlebotのクロールを拒否したい場合は、robot.txtにUser-agent:Googlebotと記載します。すると、スマートフォン用Googlebot・パソコン用Googlebotのどちらかで、対象のWebサイトのクロールをGoogleに要求できます。
パソコン用Googlebot
パソコン用Googlebotは従来からあるクローラーです。パソコンから検索された際に、検索結果として表示するためのWebサイト情報を収集します。パソコン用Googlebotも、robot.txtファイルを使ってクロールを制限できます。
Googleクローラーをseoで活用する3つの方法
Googleクローラーは、SEOで活用することが可能です。
インデックスされていないページがある場合、サーチコンソールを利用してGoogleクローラーが巡回するよう申請できます。クロールされるとSEOに悪影響を及ぼす可能性があるページがある場合は、クローラーの巡回を拒否することも可能です。
また、クローラーの巡回頻度や最後に巡回した日を把握することで、クローラーが巡回しやすいページであるか、拒否したページが巡回されていないか、などを確認できます。
Googleクローラーの巡回を申請する方法
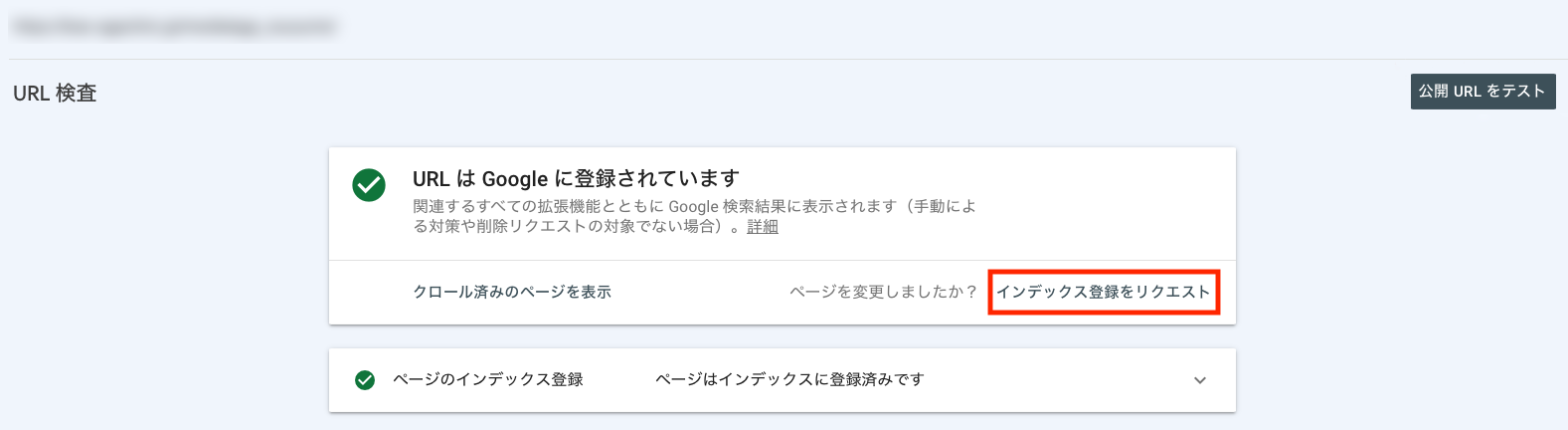
Googleクローラーの巡回は、サーチコンソールの「インデックス登録をリクエスト」から申請可能です。サーチコンソールの「URL検査」からクローラーに巡回して欲しいWebページのURLを入力し、インデックス登録をリクエストすれば申請は完了です。
ただし、クローラーの巡回を申請した時点で即クロールされるわけではありません。優先クロールキューに登録され、通常よりも早くクロールされるよう促すものであり、通常の場合は実際にクローラーが巡回するまでに24時間程度かかります。
もし数日経ってもクローラーが巡回しない場合は、ページが低品質であったり、重複コンテンツと判断されているなどの問題が考えられます。
Googleクローラーの巡回を拒否する方法
Googleクローラーの巡回を拒否する際は、robots.txtファイルを使用します。robots.txtはWordPressであればデフォルトで対応していますが、プラグインやFFTPからも設定可能です。
Googleクローラーの巡回を拒否するためのrobots.txtの書き方は、以下になります。
【robots.txtの書き方】
User-Agent:*
Disallow:/ディレクトリ名/
User-Agent:*は「全てのクローラに対して」と指定する部分であり、基本の形となります。
アスタリスク部分を「googlebot」にするとパソコン用とスマホ用のクローラーに対して、「google−image」にするとgoogle画像検索のクローラーに対して個別に指定できます。
Disallow:/ディレクトリ名/は「/ディレクトリ名/」へのクロールを拒否するという意味で、ファイル名を入力することでページごとに制限することが可能です。
その他に、ページの<head></head>内で<meta content=”noindex”>を設置することで、robots.txtの設定同様Googleクローラーの巡回を拒否することができます。
Googleクローラーがいつ来たのかを確認する方法
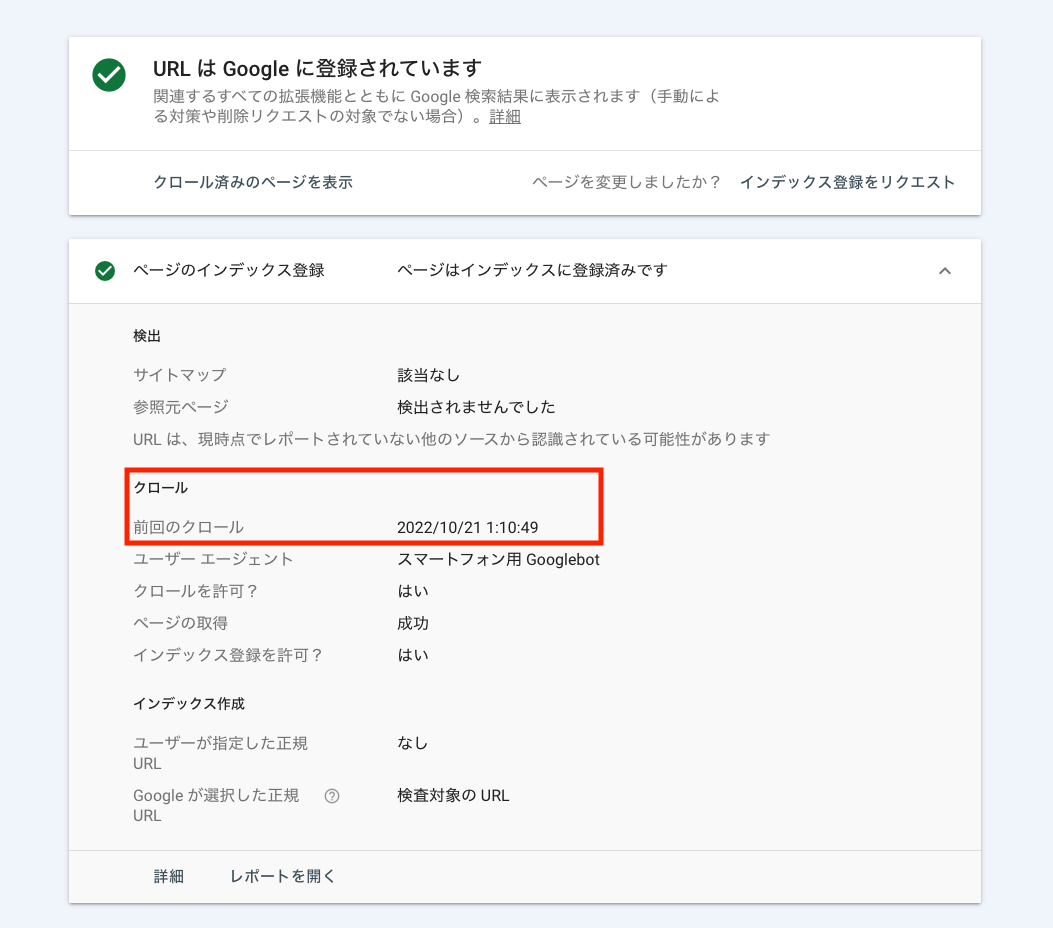
サーチコンソールを活用することで、Googleクローラーが最後にいつ来たのかを確認できます。
サーチコンソール内のURL検査から、最後にクローラーが巡回した日を確認したいページのURLを入力してみましょう。URL検査の完了画面が表示されたら、カバレッジの詳細に前回のクロールの日時が表示されます。
また、未登録と登録済みの選択肢からインデックスされない記事・インデックスされている記事ごとに、クローラーが最後に来た日付を確認できます。
まとめ
Googleクローラーは、作成したWebサイトを検索結果に表示させるための役割を持ちます。必要に応じてクローラーの巡回を拒否することで、SEOへの悪影響を対策することも可能です。サイトを公開したら、まずはサーチコンソールを活用して巡回を申請しましょう。クロールされやすいWebサイトを構築すれば集客にきっと繋げられるはずです。
- SEO対策でビジネスを加速させる

-
SEO対策でこんな思い込みしていませんか?
- 大きいキーワードボリュームが取れないと売上が上がらない・・
- コンサルに頼んでもなかなか改善しない
- SEOはコンテンツさえ良ければ上がる
大事なのは自社にあったビジネス設計です。
御社の課題解決に直結するSEO施策をご提案します
- プロフィール
-

-
GMO TECH株式会社



- 2012年より一貫して検索エンジン領域のコンサルティング業務に従事。 2017年にGMO TECH社に参画。営業組織の構築、新商材開発、マーケティング部門立ち上げをおこなう。 現在、MEOコンサルティング、SEOコンサルティング、運用型広告などSEM領域全体を統括し、 お客様の期待を超える価値提供を行うため日々、組織運営・グロースに奔走している。
-
GMO TECH株式会社
 シェア
シェア




