


Googleクローラーとは?仕組み・種類とSEOで巡回を最適化する方法【2026年最新】

この記事では、Googleクローラーの役割や代表的な種類、SEOで活用する具体的な方法を解説していくので、ぜひ参考にしてください。
「記事を更新・公開してもなかなか検索結果に出てこない」「クローラーに正しく巡回させてサイトの評価を上げたいが、何から手をつければいいかわからない」。SEOやWeb集客の担当者であれば、一度はこうした壁に突き当たったことがあるのではないでしょうか。
その鍵を握るのがGoogleクローラー(Googlebot)です。Googleクローラーとは、Web上のページを自動で巡回・収集し、Googleの検索インデックスに登録するための情報収集プログラムを指します。クローラーがページを正しく発見・処理できなければ、どれほど優れたコンテンツも検索結果には表示されません。SEOの出発点は「クローラーに正しく巡回してもらうこと」にあるのです。
本記事では、Googleクローラーの仕組みと種類を2026年最新の公式仕様で整理したうえで、SEOで巡回を「促進する・制御する・確認する」具体的な手順までを一気通貫で解説します。クロールバジェットやレンダリング、robots.txt・XMLサイトマップの設定、さらに生成AI時代のクローラー対策まで網羅しているので、自社サイトのインデックスと評価を高めるための実務に、そのまま落とし込めます。
Googleクローラー(Googlebot)とは|SEOにおける役割
👉 このパートをまとめると!
- Googleクローラー(Googlebot)はWebページを自動収集しインデックスに登録するプログラム
- 「クロール→インデックス→ランキング」の最初の入口を担う
- クローラーに発見されなければ検索結果には表示されない
Googleクローラー(Googlebot)とは、World Wide Web上のページを自動で巡回し、その内容をGoogleの検索インデックス(検索用データベース)へ登録するために情報を収集するプログラムです。「スパイダー」「ロボット(bot)」「ボット」とも呼ばれ、リンクをたどってWeb全体を網の目のように移動することから、こうした呼称が生まれました。
検索エンジンがユーザーに検索結果を返すまでには、大きく分けて「クロール(収集)→インデックス(登録)→ランキング(順位付け)」という3つの段階があります。Googleクローラーが担うのは、このうち最初の「クロール」の工程です。いわばクローラーは検索エンジンにとっての「目」であり、Web上のどこにどんなページが存在するのかを発見し、その中身をGoogleへ持ち帰る役割を果たしています。検索の仕組み全体については、関連記事のSEOの仕組みとは?検索エンジンの構造と関係性について解説で詳しく整理しています。
ここで重要なのは、クローラーに発見・処理されなければ、そのページはインデックスに登録されず、検索結果に一切表示されないという点です。たとえば、丁寧に作り込んだ新しい記事を公開しても、クローラーがその存在に気づかなければ、ユーザーがどんなキーワードで検索しても永遠にヒットしません。逆に、どこからもリンクされていない孤立したページであっても、サイトマップなどでクローラーに知らせれば発見してもらえます。SEOの第一歩が「クローラーに正しく巡回してもらうこと」だと言われるのは、このためです。
Googleクローラーは、ユーザーが検索した際に最適な情報を返せるよう、HTMLだけでなくCSS・JavaScript・画像・動画・PDFなど、ページを構成するさまざまなファイルを取得します。CSSやJavaScriptはページの見た目や動作を再現するために読み込まれ、その結果はランキング評価にも影響します。つまりGoogleクローラーは、単にテキストを集めるだけの存在ではなく、ページを「ユーザーが見るのと同じ姿」で理解しようとする精緻な仕組みなのです。
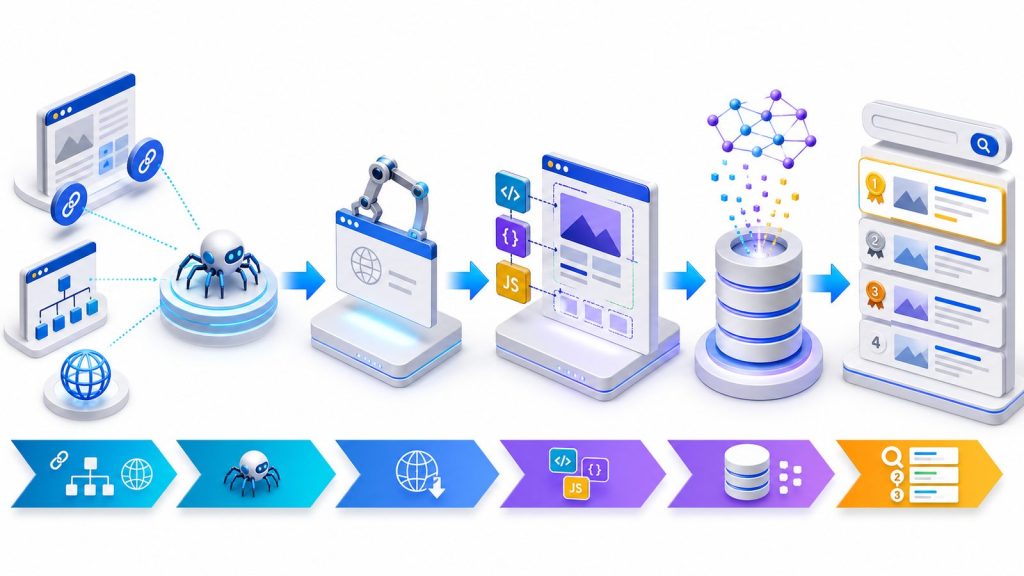
Googleクローラーがページを処理する仕組み(クロール→レンダリング→インデックス→ランキング)
👉 このパートをまとめると!
- 処理は「URL発見→クロール→レンダリング→インデックス→ランキング」の5段階
- JavaScriptはヘッドレスChromiumでレンダリングして実行・評価される
- クロールはファイルの最初の15MBが対象(2026年現在のGoogle公式仕様)
GoogleクローラーがURLを見つけてから検索結果に並ぶまでの処理は、ひとつながりのパイプラインになっています。流れを5段階で整理すると、自社サイトのどこにボトルネックがあるのかを切り分けやすくなります。
- URLの発見(クロールキュー):既知ページ内のリンク、XMLサイトマップ、外部サイトからのリンクなどを手がかりに、クロール対象となるURLのリストを作成します。
- クロール(取得):Googlebotが各URLにアクセスし、HTMLや関連リソース(CSS・JavaScript・画像など)を取得します。
- レンダリング(描画):取得したコードを実際にブラウザのように描画し、ページの最終的な姿を再現します。
- インデックス(登録):描画したページの内容を解析し、トピック・キーワード・構造化データなどを抽出して検索インデックスに登録します。
- ランキング(順位付け):ユーザーの検索クエリに対し、関連性や品質、利便性などを総合評価して表示順位を決定します。
この5段階のなかでも、SEO担当者が見落としがちなのが3番目の「レンダリング」です。現代のWebサイトはJavaScriptで内容を動的に表示するものが多く、Googleは「ヘッドレスChromium」と呼ばれる画面表示を伴わないブラウザでJavaScriptを実行し、最終的に生成されるコンテンツを評価します。
たとえば、商品一覧をJavaScriptで後から読み込む構成のECサイトでは、レンダリングが正しく行われなければ商品情報がインデックスされないことがあります。一方、記事本文を最初からHTMLに含めているブログでは、レンダリングの負担が小さく、発見からインデックスまでがスムーズに進みやすい傾向があります。
2026年最新のGoogleクローラー公式仕様
Googleクローラーの挙動を正しく理解するうえで、Google検索セントラル(Google Search Central)が公開する技術仕様を押さえておくことが欠かせません。Googleの公式ドキュメント「Googleクローラー(ユーザーエージェント)の概要」によれば、2026年現在のGooglebotには以下の仕様があります。
| 項目 | 2026年時点の公式仕様 | SEO上の意味 |
|---|---|---|
| 対応プロトコル | HTTP/1.1 と HTTP/2 の両方に対応(デフォルトはHTTP/1.1) | HTTP/2はサーバー・クローラー双方のリソースを節約。利用してもランキングへの影響はない |
| 対応圧縮形式 | gzip / deflate / Brotli(br) | 圧縮転送で帯域を節約でき、クロール効率の改善につながる |
| クロール上限 | ファイルの最初の15MBのみをクロール(デフォルト) | 巨大なHTMLでは重要コンテンツを15MB以内の前半に置くことが望ましい |
| HTTPキャッシュ | ETag/If-None-Match、Last-Modified/If-Modified-Since に対応 | ETagの利用が推奨。更新がないページの再取得を省きクロールを効率化 |
| インフラ | 数千台のマシンで分散実行し、世界中の複数データセンターからアクセス | 複数IPからのアクセスが記録される。特定IPだけを遮断する設計は危険 |
✍️ 専門家の経験からの一言アドバイス
【結論】: 「15MB上限」はほとんどの記事サイトでは問題になりませんが、大規模ECや不動産ポータルでは注意が必要です。
私たちのテクニカルSEO支援では、1ページのHTMLが肥大化し、重要な内部リンクやテキストが15MBより後ろに配置されていたために、一部コンテンツがクロールされていなかったケースに遭遇したことがあります。インラインで大量のデータやBase64画像を埋め込んでいる場合は、HTMLサイズを実測して確認することをおすすめします。
これらの仕様は、競合記事の多くがまだ反映できていない最新情報です。クローラーがどのようにファイルを取得・キャッシュするかを理解しておくことで、後述するクロールバジェットの最適化やクローラビリティ改善の打ち手の精度が大きく変わってきます。
Googleクローラーの代表的な種類
👉 このパートをまとめると!
- Googleのクローラーは公式に「一般的/特殊用途/ユーザートリガー型」の3カテゴリに分類される
- Googlebotにはスマホ用とPC用があり、現在はスマホ用が主役(モバイルファーストインデックス)
- 画像・動画・ニュース用など用途別のクローラーも存在する
「Googleクローラー」と一口に言っても、実際には用途ごとに複数のクローラーが存在します。Google検索セントラルの公式ドキュメントでは、Googleのクローラーを次の3つのカテゴリに分類しています。
- 一般的なクローラー:Googlebotをはじめ、Googleの各種プロダクトで使われる標準的なクローラーです。自動クロールの際は常にrobots.txtのルールに従います。検索結果の構築に使われる中心的な存在です。
- 特殊なケース用クローラー:特定のサービス向けに動作するクローラーで、AdsBot(広告の品質チェック用)などが該当します。サービスの性質上、robots.txtの扱いに例外がある場合があります。
- ユーザートリガー型フェッチャー:ユーザーの操作をきっかけに動作するもので、Google Search ConsoleのURL検査ツールなどが該当します。ユーザーがリクエストした瞬間にページを取得します。
このうち、SEO担当者が日常的に意識すべきは「一般的なクローラー」、とりわけGooglebotです。Googlebotにはさらに以下の2種類があります。
スマートフォン用Googlebot
スマートフォン用Googlebotは、モバイル端末でページを閲覧するユーザー視点でサイトの情報を収集するクローラーです。スマートフォンでの表示速度やレイアウト、操作性といったモバイルでの使い勝手を評価します。
ここで非常に重要なのがモバイルファーストインデックス(MFI)です。これは、Googleが原則としてスマートフォン版のページを基準にインデックス登録・評価を行う仕組みで、現在のWeb全体ですでに標準となっています。つまり、PCサイトだけ作り込んでスマホ表示が貧弱だと、評価そのものが下がってしまいます。スマートフォン用Googlebotが「主役」になっている、と理解しておきましょう。
パソコン用Googlebot
パソコン用Googlebotは、PCでの検索結果に表示するためのページ情報を収集する、従来から存在するクローラーです。モバイルファーストインデックスへ移行した現在でも、PCでの表示確認のために併用されています。ただし評価の主軸はスマートフォン用Googlebotに移っているため、SEO施策はモバイル表示を前提に設計するのが基本です。
画像・動画・ニュース用などの専用クローラー
Googleはこのほかにも、用途に応じた専用クローラーを運用しています。代表的なものは以下のとおりです。
- Googlebot-Image:Google画像検索向けに画像ファイルを収集します。alt属性やファイル名が適切だと、画像検索からの流入につながりやすくなります。
- Googlebot-Video:動画コンテンツを収集し、動画検索やリッチリザルトに活用します。動画のサムネイルや構造化データの整備が露出に影響します。
- Googlebot-News:ニュース性の高いコンテンツを収集し、Google ニュースへの掲載に利用します。
これらの専用クローラーは、robots.txtで個別のユーザーエージェントを指定して、特定の種類のクロールだけを制御することも可能です。各クローラーの正確なユーザーエージェント名は、Google公式のGoogleクローラー一覧で確認できます。
Googleクローラーの巡回を促す(発見させる)方法

👉 このパートをまとめると!
- 巡回を促す基本は「URL検査でのインデックス登録リクエスト」「XMLサイトマップ送信」「内部リンク」「外部リンク」
- インデックス登録リクエストは即時反映ではなく優先キューへの登録
- サイトマップと内部リンクの整備が継続的なクロール促進の土台になる
ページを公開しただけでは、クローラーがすぐに訪れてくれるとは限りません。とくに新規ドメインや公開直後の記事は、クローラーに「ここに新しいページがある」と能動的に知らせることで、発見・インデックスまでの時間を短縮できます。ここでは、Googleクローラーの巡回を促す代表的な4つの方法を、実行手順とともに解説します。
方法1:URL検査ツールでインデックス登録をリクエストする
公開したばかりの個別ページを最速でクローラーに知らせたいときに使うのが、Google Search Console(GSC)のURL検査ツールです。手順は次のとおりです。
- Google Search Consoleにログインし、対象サイトのプロパティを選択する
- 画面上部の検索窓に、クロールしてほしいページのURLを入力する
- 「URLがGoogleに登録されています」または「登録されていません」の結果が表示される
- 「インデックス登録をリクエスト」をクリックする
ここで押さえておきたいのは、リクエストした瞬間にクロール・インデックスされるわけではないという点です。リクエストは優先的にクロールされるキュー(順番待ちの列)への登録を促すもので、実際の反映までには時間がかかります。Google公式も、同じURLを繰り返しリクエストしてもクロールが早まるわけではないと説明しています。
数日待ってもインデックスされない場合は、ページの品質や重複の問題が考えられます。インデックスされない原因の切り分けは、Googleにインデックス登録されない理由と対策方法を解説で詳しく解説しています。
方法2:XMLサイトマップを作成・送信する
サイト全体の構造を一覧でクローラーに伝える手段がXMLサイトマップです。サイト内の主要URLを記載したファイルで、特にページ数の多いサイトや、内部リンクだけでは到達しにくいページがあるサイトで効果を発揮します。送信手順は以下のとおりです。
- XMLサイトマップを生成する(WordPressならYoast SEOやAll in One SEOなどのプラグイン、または専用ツールで自動生成できる)
- 生成された
sitemap.xmlをサーバーのルートディレクトリにアップロードする - Google Search Consoleの「サイトマップ」メニューを開く
- サイトマップのURL(例:
https://example.com/sitemap.xml)を入力して「送信」する
送信後は、GSC上で「成功しました」と表示されるか、検出されたURL数が想定どおりかを確認します。サイトマップは作成して終わりではなく、ページの追加・更新に合わせて最新の状態に保つことが、継続的なクロール促進につながります。詳しい仕様はGoogle公式のサイトマップの作成と送信を参照してください。
方法3:内部リンク・パンくずリストを整える
クローラーはリンクをたどってページからページへと移動します。そのため、サイト内の内部リンク設計はクロール促進の土台になります。関連性の高い記事同士を文脈に沿ってリンクで結ぶことで、クローラーがサイトの深い階層まで到達しやすくなり、ページ同士の関係性も伝わりやすくなります。
あわせてパンくずリストを設置すると、サイトの階層構造がクローラーとユーザーの双方に明確になります。パンくずリストには構造化データ(BreadcrumbList)を付与しておくと、検索結果での表示にも活用されます。
方法4:外部サイトからのリンク(被リンク)を獲得する
他サイトに自社ページへのリンクが貼られると、クローラーはそのリンクをたどって新しいページを発見します。これが外部リンク(被リンク)による発見ルートです。質の高い被リンクは、クローラーの発見を助けるだけでなく、ページの信頼性・権威性のシグナルにもなります。
ただし、購入リンクや相互リンクの過剰な交換といった人為的なリンク操作はGoogleのスパムポリシーに違反するため、あくまでコンテンツの価値に基づいて自然に獲得することが大前提です。
✍️ 専門家の経験からの一言アドバイス
【結論】: 「公開したのにインデックスされない」と相談を受けたとき、私たちがまず確認するのは「内部リンクで到達できるか」「サイトマップに含まれているか」の2点です。
URL検査での個別リクエストは即効性がありますが、根本的には内部リンクとサイトマップでクローラーが自然に回遊できる構造をつくることが、サイト全体のインデックス改善には欠かせません。
サイトの規模が大きくなるほど、こうしたクローラビリティの設計は手作業では追いきれなくなります。内部リンク構造やクロール状況を可視化して改善したい場合は、サイト全体を診断できるツールの活用も選択肢になります。クローリングの課題を網羅的に洗い出したい場合は、テクニカルSEOの専門ツール「Lumar」のクローリング診断もご検討ください。
クロールされない原因を、サイト全体から自動で洗い出す
内部リンク切れ・重複URL・ソフト404・クロール阻害要因を可視化。テクニカルSEOの専門ツール「Lumar」で、クローラビリティの課題を網羅的に診断できます。
Googleクローラーの巡回を制御する方法(robots.txt / noindex / robots meta)
👉 このパートをまとめると!
- robots.txtは「クロールしてほしくないページ」をクローラーに伝えるファイル
- noindexは「インデックスに登録しないでほしい」指示で、robots.txtとは役割が異なる
- noindexを効かせるにはrobots.txtでブロックしてはいけない(クロールできないとnoindexを認識できない)
サイトには、検索結果に出したくないページ(管理画面、テスト用ページ、サンクスページなど)や、クロールさせる価値の低いページが存在します。こうしたページを適切に制御することは、クロールの無駄を減らし、重要なページにクローラーのリソースを集中させるうえで重要です。制御の手段にはrobots.txtとnoindexがあり、この2つは役割がまったく異なります。混同するとインデックスのトラブルにつながるため、違いを正確に理解しておきましょう。
robots.txtでクロール自体を制御する
robots.txtは、サイトのルートディレクトリに設置し、「どのクローラーに、どのパスをクロールさせるか/させないか」を伝えるテキストファイルです。基本的な書き方は以下のとおりです。
Disallow: /example-directory/
User-agent: * は「すべてのクローラーに対して」という指定で、ここを Googlebot にすればGooglebot、Googlebot-Image にすれば画像用クローラーへの個別指定になります。Disallow: /example-directory/ は「その配下のクロールを禁止する」という意味です。
ここで注意すべき2点があります。1つ目は、robots.txtは「クロールを制御するもの」であって、「検索結果からの除外を保証するものではない」ことです。robots.txtでブロックしても、他サイトからリンクされていれば、URL自体が検索結果に表示されることがあります。2つ目は、Google公式も明記しているとおり、robots.txtは絶対的な命令ではなく、悪意あるクローラーがこれを無視する可能性がある点です。機密情報の保護にはrobots.txtではなく、パスワード保護などの仕組みを使う必要があります。robots.txtの正確な記法はGoogle公式のrobots.txt の書き方、設定と送信を参照してください。
noindexで検索結果からの除外を指示する
「検索結果に表示させたくない」ことが目的なら、使うべきはnoindexです。noindexは、ページの <head> 内にmetaタグとして記述するか、HTTPレスポンスヘッダー(X-Robots-Tag)として返す方法があります。
このタグを設置すると、Googleはそのページをインデックスから除外します。PDFや画像などHTML以外のファイルには、X-Robots-Tag: noindex というHTTPヘッダーを使います。
【最重要】noindexとrobots.txtを併用してはいけない理由
ここが、多くのサイトで起きる落とし穴です。「このページを検索結果から消したい」と考えて、noindexタグを設置すると同時に、robots.txtでそのページをブロックしてしまうケースがありますが、これは逆効果になります。
理由はシンプルです。Googleがページに設置された noindex タグを「読む」ためには、まずそのページをクロールできる必要があるからです。robots.txtでクロールをブロックしてしまうと、Googlebotはページの中身(=noindexタグ)を確認できず、結果としてnoindexの指示が認識されません。Google公式も「noindex ルールを有効にするには、robots.txtでページをブロックせず、クローラーがアクセスできるようにする必要がある」と明記しています。
正しい運用は、「検索結果から確実に消したいページはnoindexを使い、robots.txtではブロックしない」ことです。すでにインデックスされているページを除外したい場合は、noindexを設置し、Googleがそのページを再クロールしてnoindexを認識するのを待ちます。除外が完了してから、必要に応じてrobots.txtでのクロール制御を検討する、という順序が安全です。
クロールバジェットとクローラビリティの最適化
👉 このパートをまとめると!
- クロールバジェットとは、Googleが一定期間にサイトをクロールするリソースの総量
- 気にすべきは大規模サイト(100万ページ超)や頻繁に更新される中規模サイト(1万ページ超)
- 重複・ソフト404・無限スペースの解消とサイト高速化がクロール効率を高める
サイトの規模が大きくなると、「クローラーが全ページを回りきれない」という問題が生じます。ここで理解しておきたいのがクロールバジェットという考え方です。クロールバジェットとは、Googleが一定期間内に特定のサイトをクロールするために割り当てるリソースの総量を指し、大きく次の2つの要素で決まります。
- クロール能力の上限(crawl capacity limit):サイトに負担をかけずにクロールできる同時接続数と取得間隔の上限。サーバーの応答が速く安定しているほど上限は高くなります。
- クロールの需要(crawl demand):そのサイト・ページをどれだけ頻繁にクロールしたいかという需要。人気度が高く、更新頻度の高いページほど需要が高まります。
クロールバジェットを気にすべきサイトの基準
すべてのサイトがクロールバジェットを神経質に気にする必要はありません。Google公式の「大規模なサイトのクロール バジェット管理」によれば、対象となるのは以下のようなサイトです。
| サイトの規模 | 目安 | クロールバジェットの重要度 |
|---|---|---|
| 大規模サイト | 重複のないページが100万以上で、週1回程度更新 | 高い |
| 中規模以上のサイト | 重複のないページが1万以上で、毎日更新される | 高い |
| 上記以外の一般的なサイト | 数百〜数千ページ規模 | 通常は気にしなくてよい |
数百ページ規模の中小サイトであれば、Googleは通常問題なく全ページをクロールできるため、クロールバジェットよりもコンテンツの質や内部リンクの整備を優先するほうが効果的です。一方、ECサイトや大型メディアのように動的にURLが増えるサイトでは、クロールバジェットの最適化がインデックス数に直結します。
クロールバジェットを浪費する要因と対策
Google公式は、クロールバジェットを無駄に消費する要因をいくつか挙げています。これらを解消することが最適化の基本です。
- 重複コンテンツ:同じ内容のページが複数のURLで存在すると、クローラーが重複ページに何度もアクセスして無駄が生じます。canonicalタグで正規URLを指定し、評価を集約しましょう。
- URLパラメータによる無限のURL生成:絞り込み検索やセッションIDなどで膨大なURLバリエーションが生まれると、クロールが浪費されます。パラメータの扱いについてはURLパラメータとは?シーン別活用方法と設定方法を解説で整理しています。
- ソフト404エラー:実際には存在しないページなのに200(正常)ステータスを返してしまうと、Googleは無効なページをクロールし続けてバジェットを浪費します。正しく404/410を返すことが重要です。対処法はソフト404エラーとは?SEOへの影響・原因の4分類・確認方法・対処法を解説【2024年最新】で詳しく解説しています。
- 長いリダイレクトチェーン:リダイレクトが何段も連鎖すると、その分クロールの手間が増えます。リダイレクトはできるだけ1回で目的ページに到達させましょう。
Core Web Vitals・ページ速度との関係
ページの表示速度は、クロール効率にも関わります。サーバーの応答が速く、ページが軽量であれば、Googleは同じ時間でより多くのページをクロールできます。ユーザー体験の指標であるCore Web Vitals(LCP・INP・CLSの3指標)は直接の「クロール」指標ではありませんが、ページ表示の最適化はクロール能力の上限を引き上げる効果があり、かつランキング評価の一要素でもあります。クローラビリティとユーザー体験の改善は、同じ「ページ高速化」という打ち手で両立できるのです。
✍️ 専門家の経験からの一言アドバイス
【結論】: クロールバジェットの最適化で私たちが最初に着手するのは、「クロールされる価値のないページ」をクローラーの視界から外すことです。
検索意図に応えない自動生成ページ、重複したパラメータURL、ソフト404を整理するだけで、重要なページへのクロールが集中し、新規記事のインデックスがスムーズになりやすくなります。クロールバジェットは「増やす」より「無駄を減らす」発想が実務では効きます。
クローラビリティの改善は、内部リンク設計・URL正規化・ステータスコード管理・サイト高速化など、多岐にわたるテクニカルSEOの総合力が問われる領域です。自社だけで全体像を診断・改善するのが難しい場合は、専門家のサポートを活用することで、優先順位の高い課題から効率よく着手できます。
Googleクローラーの巡回状況を確認する方法
👉 このパートをまとめると!
- クロール状況はGoogle Search Consoleの「クロール統計情報」と「URL検査」で確認できる
- URL検査では最終クロール日時やインデックス状況を個別に把握できる
- 「site:」検索でインデックス済みページの概数を簡易チェックできる
クロールを促進・制御したら、次は「実際にクローラーがどう動いているか」を確認し、改善のサイクルを回します。Googleクローラーの巡回状況を確認する代表的な3つの方法を紹介します。
方法1:クロール統計情報レポートで全体傾向をつかむ
Google Search Consoleのクロール統計情報レポート(設定メニュー内)では、サイト全体に対するクロールの傾向を確認できます。具体的には、一定期間のクロールリクエストの総数、平均応答時間、ホストのステータス、ファイルタイプ別・目的別(更新/検出)のクロール内訳などが表示されます。クロールリクエストが急減したり、応答時間が急増したりしている場合は、サーバーの不調やサイト構造の問題が疑われます。大規模サイトのクロールバジェット監視に有効なレポートです。
方法2:URL検査ツールで個別ページを確認する
特定のページについて詳しく確認したいときは、URL検査ツールを使います。対象URLを入力すると、以下の情報が得られます。
- そのページがインデックスに登録されているか
- 最後にクロールされた日時(前回のクロール)
- 検出された問題(クロールエラー、noindexの有無など)
- レンダリング後のページの状態(スクリーンショットやHTML)
「公開した記事がいつクロールされたのか」「なぜインデックスされないのか」を切り分ける際の出発点になります。
方法3:「site:」検索でインデックス状況を簡易チェックする
最も手軽な確認方法が、Google検索で site:example.com のように入力する「site:」検索です。自社ドメインのインデックス済みページの概数を把握できます。ただし、ここで表示される件数はあくまで概算であり、正確なインデックス数を示すものではありません。厳密なインデックス状況は、GSCの「ページ(インデックス登録)」レポートで確認するのが確実です。
これら3つの確認手段を組み合わせ、「促進・制御の施策がクロールにどう反映されたか」を定期的にチェックすることで、クローラビリティ改善のPDCAを回せるようになります。
生成AI時代のクローラーとGEO/AIO対策

👉 このパートをまとめると!
- 近年はGPTBotやGoogle-Extendedなど、生成AI向けのクローラーが増えている
- AIクローラーの収集可否はrobots.txtで個別に制御できる
- 構造化データの整備はSEOとAI検索(GEO/AIO)双方の可視性を高める
2026年現在、Webサイトを巡回するのはGoogleやBingといった検索エンジンのクローラーだけではありません。生成AIのためのクローラーが急速に存在感を増しています。AI検索(生成AIによる回答生成)が普及するなか、自社コンテンツがAIにどう収集・引用されるかという視点が、SEOの新しい論点になっています。
代表的な生成AIクローラー
- GPTBot:OpenAIが運用する、ChatGPTなどのモデルの学習・改善のために情報を収集するクローラーです。
- OAI-SearchBot:OpenAIの検索関連機能のためのクローラーで、AI検索の結果にコンテンツを反映する用途で動作します。
- Google-Extended:Googleの生成AI(Geminiなど)向けに、コンテンツの利用可否を制御するためのユーザーエージェントです。
これらのAIクローラーは、検索エンジンのクローラーと同様に、robots.txtで個別に収集の可否を制御できます。たとえば、自社コンテンツをAIの学習に使わせたくない場合は、robots.txtで該当するユーザーエージェントをDisallowに指定する、という対応が可能です。逆に、AI検索での露出を狙うなら、AIクローラーのアクセスを許可しておく判断もあります。どちらが正解かは、ブランドの方針やコンテンツの性質によって異なります。
GEO/AIO観点での構造化データの重要性
AI検索の時代に重要性を増しているのが、構造化データ(JSON-LD)です。構造化データは、ページの内容を「これは記事です」「これはFAQです」と機械可読な形で明示するもので、検索エンジンだけでなく生成AIがコンテンツの意味を正確に理解する助けになります。これは、AIに引用・参照されやすくするための最適化、すなわちGEO(Generative Engine Optimization)/AIO(AI Optimization)の基盤施策と言えます。
クローラー対策は、もはや「検索エンジンに正しくクロールしてもらう」だけにとどまりません。「検索エンジンとAIの双方に、正しく内容を理解してもらう」ための入口として捉え直す段階に来ています。構造化データの実装方法はjson-ldの仕組みとは?SEO効果と構造化マークアップの方法を解説で、上位表示の総合的な考え方はGoogle検索で上位表示させる方法とは?仕組みから実装ガイド、最新トレンドまで完全解説で詳しく解説しています。
よくある質問(FAQ)
👉 このパートをまとめると!
- クローラーの巡回頻度・新規サイトの対処・robots.txtの効力など、現場で多い疑問をまとめた
- 巡回頻度はサイトの更新性や人気度で変わり、一律の周期はない
- robots.txtは検索結果からの除外を保証しないため、目的に応じてnoindexと使い分ける
Q1. Googleクローラーはどのくらいの頻度で巡回しますか?
一律の周期は決まっていません。クロールの頻度は、サイトの更新頻度・人気度・サーバーの応答性などから決まる「クロールの需要」と「クロール能力の上限」によって変動します。頻繁に更新され、多くの被リンクを持つ人気サイトほど巡回頻度は高くなる傾向があります。逆に、ほとんど更新されないサイトはクロール頻度が下がります。更新時に内容が変わったことをクローラーに認識させるには、サイトマップの更新やコンテンツの実質的な更新が有効です。
Q2. 新規サイトにクローラーが来ない場合はどうすればいいですか?
新規ドメインは、Googleにまだ認知されていないため、クロールが始まるまで時間がかかることがあります。対処としては、(1)Google Search Consoleにサイトを登録する、(2)XMLサイトマップを送信する、(3)URL検査ツールで主要ページのインデックス登録をリクエストする、(4)他サイトからの自然な被リンクを獲得する、といった施策が有効です。これらを行ってもしばらく反映されないのは新規サイトでは珍しくないため、一定期間は様子を見ることも必要です。
Q3. robots.txtでブロックすれば検索結果から消えますか?
いいえ、確実には消えません。robots.txtはクロールを制御するものであり、検索結果からの除外を保証しません。他サイトからリンクされていると、クロールされていなくてもURLが検索結果に表示されることがあります。検索結果から確実に消したい場合は、robots.txtでブロックせず、ページにnoindexを設置してください。
Q4. クローラーがサーバーに過剰な負荷をかけることはありますか?
通常、Googlebotはサーバーに過度な負担をかけないよう、クロール能力の上限を自動で調整します。ただし、サーバーの応答が極端に遅い場合や、何らかの理由でクロールが集中した場合に負荷が問題になることがあります。その場合は、Google Search Consoleからクロール頻度を一時的に下げるよう要請することも可能です。
Q5. JavaScriptで表示するコンテンツはクロール・インデックスされますか?
されます。GoogleはヘッドレスChromiumでJavaScriptを実行(レンダリング)し、生成されたコンテンツを評価します。ただし、レンダリングには追加のリソースと時間がかかるため、重要なコンテンツはできるだけ最初のHTMLに含めておくと、発見からインデックスまでが安定しやすくなります。
まとめ|Googleクローラーを味方につけてSEOを加速する
👉 このパートをまとめると!>
- クローラーの仕組みを理解し「促進・制御・確認」のサイクルを回すことがSEOの土台
- 2026年の公式仕様(3カテゴリ・15MB・HTTP/2・レンダリング)を押さえることが差別化につながる
- クローラビリティ改善は専門性が高く、ツールや専門家の活用が有効
Googleクローラー(Googlebot)は、Web上のページを収集し検索インデックスに登録する、SEOのすべての出発点です。本記事では、その仕組みを「クロール→レンダリング→インデックス→ランキング」の5段階で整理し、2026年最新の公式仕様(クローラーの3カテゴリ分類、15MBのクロール上限、HTTP/2・Brotli対応、ETag推奨、ヘッドレスChromiumによるレンダリング)を踏まえて解説しました。
実務で重要なのは、クローラーに対して「発見させる→巡回を促す→制御する→確認・改善する」という運用サイクルを回すことです。URL検査ツールやXMLサイトマップ、内部リンクで巡回を促し、robots.txtとnoindexを正しく使い分けて制御し、クロール統計情報やURL検査で状況を確認する。この一連の流れを習慣化することで、新規ページのインデックス速度やサイト全体の評価は着実に改善していきます。
さらに、生成AIクローラーへの対応と構造化データの整備は、検索エンジンとAI検索の双方で可視性を高める新しい最適化軸です。「クローラー最適化=SEOとAI可視性の入口」という視点を持つことが、これからのWeb集客では大きな差を生みます。
一方で、クロールバジェットの最適化やクローラビリティの診断は、内部リンク・URL正規化・ステータスコード・サイト高速化など、テクニカルSEOの総合力が問われる領域です。「やるべきことは分かったが、自社サイトのどこから手をつければいいか分からない」という場合は、専門ツールや支援サービスを活用するのが近道です。GMO TECHでは、クローリング診断からテクニカルSEO改善まで、サイトの状況に合わせた支援を提供しています。クローラーを味方につけ、検索とAIの両方で成果を伸ばしていきましょう。
クローラビリティ改善とテクニカルSEOを、プロと一緒に進める
クロールの最適化からインデックス改善、検索順位の向上まで。GMO TECHのSEO支援が、サイトの課題に合わせた打ち手を提案します。まずは資料で支援内容をご確認ください。
監修・執筆: 大澤 健人(GMO TECH株式会社 / SEO・コンテンツマーケティング担当)
公開日: 2022年3月7日 / 最終更新日: 2026年7月10日
- SEO対策でビジネスを加速させる

-

SEO対策でこんな思い込みしていませんか?
- 大きいキーワードボリュームが取れないと売上が上がらない・・
- コンサルに頼んでもなかなか改善しない
- SEOはコンテンツさえ良ければ上がる
大事なのは自社にあったビジネス設計です。
御社の課題解決に直結するSEO施策をご提案します
- プロフィール
-

-
GMO TECH株式会社



- 2012年より一貫して検索エンジン領域のコンサルティング業務に従事。 2017年にGMO TECH社に参画。営業組織の構築、新商材開発、マーケティング部門立ち上げをおこなう。 現在、MEOコンサルティング、SEOコンサルティング、運用型広告などSEM領域全体を統括し、 お客様の期待を超える価値提供を行うため日々、組織運営・グロースに奔走している。
-
GMO TECH株式会社
 シェア
シェア




