


robots.txtとは?書き方・設定方法を解説

robots.txtファイルにクローラーの巡回をブロックする旨の構文を記述し、サイトにアップロードすることで、ページごとのクロール頻度をコントロールできるようになります。
robots.txtを活用することで、重要ではないコンテンツのクロールを制御し、重要なコンテンツを適切にクロールさせることができます。クロールを最適化することでSEOに良い影響をもたらします。
徐々に自社サイトの規模が大きくなってきたと感じているWeb担当者は、この機会にrobots.txtの意味や書き方、設定方法を覚えておきましょう。
robots.txtとは?
robots.txtとは、検索エンジンにWebサイトの特定ページをクロールさせないために設定するファイルです。
Webサイトのコンテンツには上位表示させる必要がないページも含まれているため、robots.txtでクローラーの巡回を制御し、クロール頻度を上げたいページに多く巡回してもらうことが重要となります。
robots.txtを設定することで個別ページのクロールをブロックできますが、ディレクトリを指定することで、ディレクトリ配下のクロールをブロックすることも可能です。
robots.txtとnoindexとの違い
noindexとは、指定したページが検索エンジンのクローラーにインデックスされないように指示を送るメタタグのことです。ページの<head>内にnoindexタグを記述することで、検索結果画面に表示されないように指定することが可能です。
robots.txt:クロールを制御
noindex:インデックス自体を拒否
robots.txtを設定してクローラーの巡回を制御したページはユーザーが閲覧できますが、noindexタグが設置されたページはインデックスそのものが削除されるため、検索エンジンから評価されず、検索結果に表示されることはありません。
robots.txtとnoindexを使い分けるタイミング
robots.txtは、検索エンジンのクローラーの巡回を制御しますが、noindexはクロール自体を制御するものではありません。
全ページへのクローラーの巡回を特定ページにコントロールしたい場合は、robots.txtを使ってクロール範囲を狭め、検索上位を狙う必要がなく、かつ検索エンジンにインデックスされる必要もないページは、noindexタグを設置してクローラーのインデックスを拒否します。
noindexはクロールの制御をしないため、サイトの規模によってはクロールバジェットを無駄に消費することがあるため、robots.txtでの制御が必要となります。
関連記事:クロールバジェットとは?対象サイトやGoogleの見解、最適化の方法を解説
関連記事:noindexとnofollowの使い方SEO効果を上げるポイントを徹底解説
robots.txt基本の型
Webサイト内のクロール状況をコントロールできるrobots.txtですが、Google検索セントラル内でサンプルコードが公開されています。
robots.txtは3つの要素で構成されています。
- User-Agent
- Disallow
- Sitemap
以下の型を参考にしてみてください。
User-agent: *
Disallow:
Sitemap: http://www.example.com/sitemap.xmlまた、WordPressの場合は、以下のようなデフォルト設定となっています。
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: http://www.example.com/sitemap.xmlWordPressは管理フォルダーを検索エンジンからインデックスされないようにするため、Disallowで一度クロールを制御した後、Allowで「特定ページだけ」をクロールするように指示を出しています。
DisallowよりはAllowの方が強く、以上のように記述することでDisallow配下のAllowで指定したページをクロールするようになります。
通常「Allow」のコードは打ち込む必要がありませんが、WordPressを運用している方は以上のようなrobots.txtファイルがデフォルトで設定されていることを覚えておきましょう。
User-Agent
「User-Agent」とは、クロールを制御するクローラーを指定する項目です。
基本的には、全てのクローラーを対象とする「*(半角アスタリスク)」を打ち込みますが、特定のクローラーだけのクロールを制御したい場合は、特定のクローラーの「ユーザーエージェントトークン」を打ち込みます。
難しく聞こえるかもしれませんが、入力するコードは一文程度のものです。以下にGoogleが運用しているクローラーのユーザーエージェントトークンの例を記載していますので参考にしてください。
- パソコン用 Googlebot:Googlebot
- スマートフォン用 Googlebot:Googlebot
- AdSense クローラー:Mediapartners-Google
- 画像用 Googlebot:Googlebot-Image
Googleの検索エンジンからクロールされたくない場合は、パソコン・スマホ両方のクローラーを意味する「Googlebot」を記述しましょう。
Disallow
「Disallow」とは、クロールを制御するページを指定する項目を意味します。以下にrobots.txtの基本的なガイドラインからの記述例を記載します。
- ・サイト全体のクロールを禁止する構文
Disallow: / - ・ディレクトリとそのコンテンツのクロールを禁止する構文
「calendar」と「junk」を変更して使用Disallow: /calendar/ Disallow: /junk/ - ・単一ページへのクロールを禁止する構文
「private_file.html」をサイトの対象ページ名に変更して使用するDisallow: /private_file.html
Allow
「Allow」とは、Disallowで指定しているディレクトリ配下のサブディレクトリ・特定ページのクロールを指示する項目です。
サブディレクトリを指定する場合は末尾に「/(スラッシュ)」を記述し、特定ページを指定する場合はブラウザで表示される完全なページ名にする必要があります。
ただし、クローラーはデフォルトでサイト内の全てのページにクロールするようにプログラムされているため、Disallow配下のページをクロールしたい時以外は使用しません。
Sitemap
「Sitemap」とは、robots.txtファイルの対象となるWebサイトの場所を教える項目です。省略も可能とされている項目ですが、記述することで指定したクローラーが早くサイトを巡回してくれる可能性があります。
自社サイトのクローラビリティを高めるためにも記述しておきましょう。サイトマップの例として以下を参考にしてください。
- Sitemap: https://example.com/sitemap.xml
- Sitemap: http://www.example.com/sitemap.xml
robots.txtの書き方
以上の説明を踏まえて、robots.txtをUser-Agentから順に記述していきます。
なお、WordPressを使用している方は、以下のデフォルトの状態にコードを追記していく形で書いていきましょう。具体的な例としては以下のようになります。
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Disallow: /directory1/
Sitemap: https://gmotech.jp/semlabo/sitemap.xml以上のように記述することで、①全クローラーを対象に、②「directory1」配下のページクロールを制御することができます。
robots.txtの確認方法
作成した構文が正しい記述となっているかどうかは、Google Search Consoleの「robots.txtテスター」で確認することが可能です。robots.txtテスターへアクセスすると、以下のような画面が表示されます。
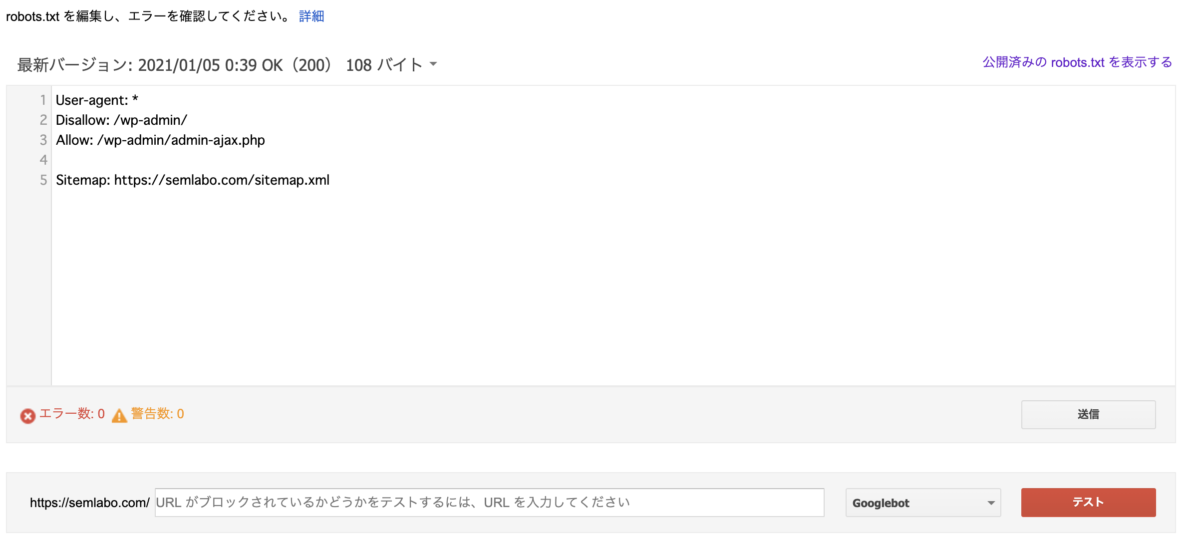
画面内の記述部分を全選択し、先ほど作成した構文を貼り付けます。
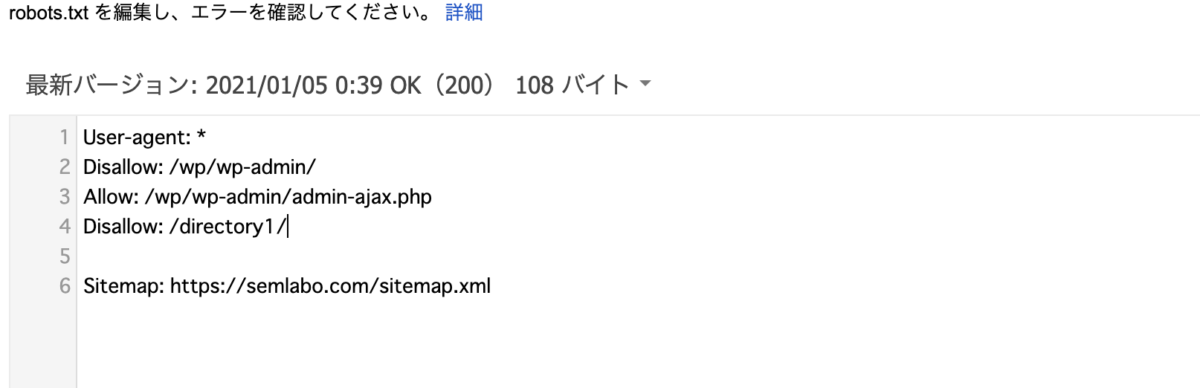
次に、Disallowで指定したディレクトリやページがブロックされているかどうかを確認する必要があります。下の画像の赤枠に囲まれた部分に、ディレクトリ名・URLを記述します。
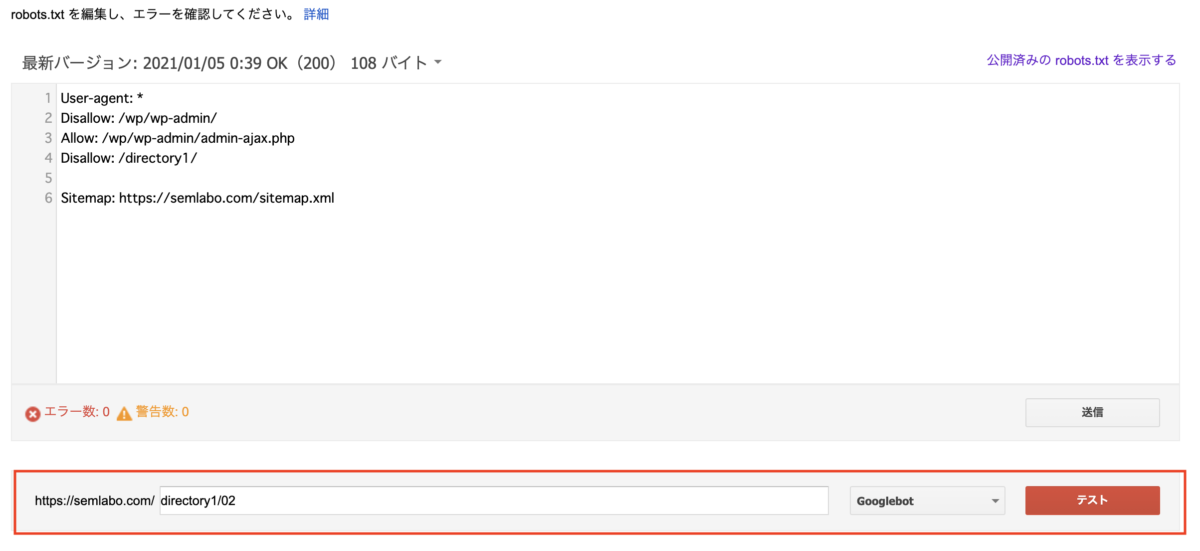
今回は例として「directory1/02」と記述しています。そして赤枠の右側に表示されている「テスト」を選択します。
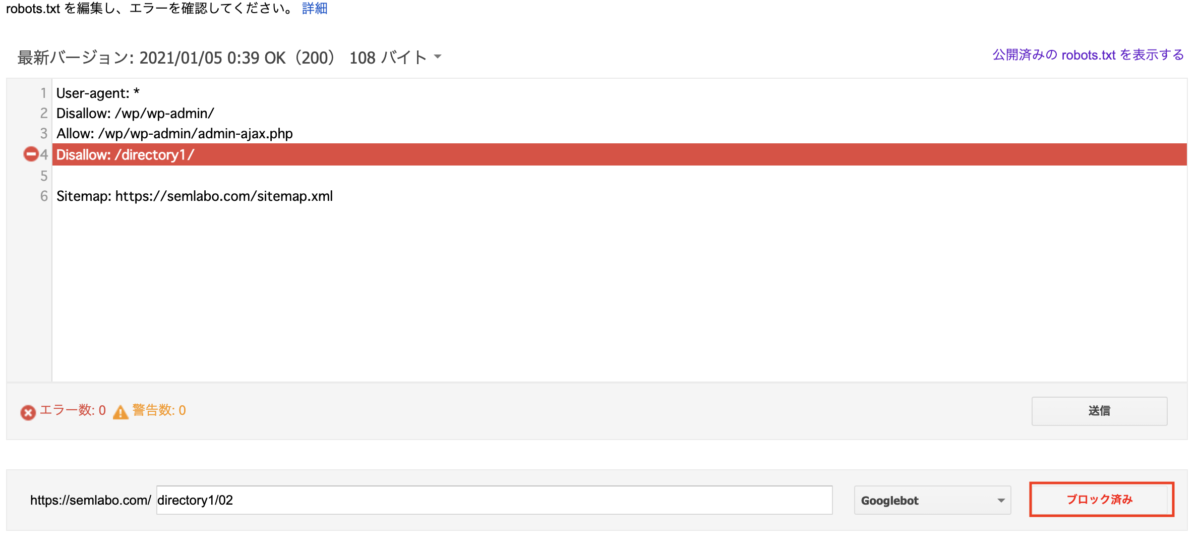
テスト実行後に、Disallowで記述した部分が赤く表示され、「ブロック済み」と表示されていれば、正しく記述できていると判断して良いでしょう。
robots.txtの設定方法
テストを終えた後は、FTPソフトを使用して、robots.txtファイルをサイトにアップロードします。
ここで注意したいのは、アップロード先をルートドメイン以外の場所に指定しないことです。robots.txtファイルは、ルートドメインにアップロードしなければ効果が発揮されないことを覚えておきましょう。
OK:http://example.com/robots.txt
NG:http://example.com/news/robots.txt
robots.txt設定時の注意点
ここまでrobots.txtの意味や役割、書き方・確認方法などを解説してきましたが、最後にrobots.txtファイルを設定する上で注意したいことについて紹介していきます。
- robots.txtで指定してもユーザーは閲覧できる
- インデックス済みページは検索エンジン上に残り続ける
- robots.txtを無視するUser-Agentも存在する
- robots.txtの内容が反映されるまでに1~2週間かかる
robots.txtはあくまで検索エンジンのクローラーの巡回を制御するファイルで、ユーザーの閲覧をブロックするものではありません。
したがって、ユーザーの目に触れてはいけない非公開コンテンツなどがある場合は、「noindex」タグを使って検索エンジン上からコンテンツを削除する必要があります。
ただし、robots.txtファイルで指定しているディレクトリ配下のページインデックスをnoindexで削除する場合は、先にrobots.txtファイルでの指定を外し、インデックスされているページにnoindexタグを設定しなければなりません。
なぜなら、robots.txtでクロールを制御していると、noindexを設定したページにクローラーが巡回しなくなるからです。
検索エンジンにページを表示させないことが目的の場合はnoindexタグを設定し、続いてrobots.txtでクローラーの訪問を阻止しましょう。
また、検索エンジンのクローラーの中には、robots.txtのDisallowの内容を無視するクローラーも存在します。
robots.txtで指定しても効果が見られない場合は、別の方法でクロールをコントロールする必要があります。
なお、Google検索エンジンのクローラー「Googlebot」と、AdSenseクローラーの「Mediapartners-Google」は、robots.txtファイルで指定されたディレクトリ・ページにはアクセスしないことを明記しています。
ただし、一部例外もあるため、気になる方はGoogleのヘルプセンターの内容を確認してください。
自社サイトのクロールコントロールにはLumar(旧:DeepCrawl)がおすすめ
robots.txtは検索エンジンのクロールを制御し、重要ページへのクローラー巡回頻度を高めることが目的ですが、自社サイトの階層構造が最適化されていなければ、いつまで経っても重要ページのクロール頻度は高めることができません。
そのような場合は、robots.txtファイルの設置前に、自社サイトの内部構造を内部SEOツールで調べる必要があります。
Lumar(旧:DeepCrawl)はサイト内のページの深さを診断し、ユーザーや検索エンジンが見つけにくいページ・コンテンツを発見して、再設置する機能を搭載しています。他にもパフォーマンスが優れている領域・セクションの判別を行い、自社サイトにおける重要ページを発掘することも可能です。
これから本格的に自社サイトの運用を行っていきたいWeb担当者は、内部SEOツールのサポートを受けることも検討してみてはいかがでしょうか。
尚、自社サイトの内部構造を最適化し、SEOで成果を出すための施策は「テクニカルSEO」と呼ばれています。
こちらの記事内で、テクニカルSEOに関する詳細と対策について紹介していますので、ぜひご覧ください。
- SEO対策でビジネスを加速させる

-
SEO対策でこんな思い込みしていませんか?
- 大きいキーワードボリュームが取れないと売上が上がらない・・
- コンサルに頼んでもなかなか改善しない
- SEOはコンテンツさえ良ければ上がる
大事なのは自社にあったビジネス設計です。
御社の課題解決に直結するSEO施策をご提案します
 シェア
シェア




