BigQueryとは?使い方や料金・特徴・活用事例を詳しく紹介

 ツイート
ツイート シェア
シェアしかし、「BigQueryって聞いたことはあるけど、実際何ができるの?」「料金はどのくらいかかるの?」という疑問をお持ちの方も多いでしょう。
この記事では、そんなBigQueryの基本から応用例、料金体系までをわかりやすく解説します。
- Google BigQueryとは
- Google BigQueryの仕組み
- カラム型データストア
- ツリーアーキテクチャ
- Google BigQueryの用途・できること
- 膨大な量のデータ解析
- データのリアルタイム分析
- API連携(Pythonでの実行)
- Google BigQueryの特徴(メリット)
- サーバーレスで専門知識が不要
- データの処理速度が高い
- 低コストで利用できる
- GA4との連携が可能
- Google BigQueryの料金
- Google BigQueryの使い方
- Google BigQueryの活用事例
- 株式会社 LIXIL
- 株式会社ぐるなび
- JapanTaxi株式会社
- 日本テレビ放送網株式会社
- 株式会社MonotaRO
- まとめ
- SEOに悩むサイト担当者必見!世界最高水準のテクニカルSEOツール「Lumar」
-

URLを入れるだけでサイト内部の問題を一括検出。
Googleと同じ視点でサイトクロール、
大規模サイトでも手軽に高度なSEO分析ができます!まずは無料デモクロールを試して、あなたのサイトの問題点を一括検出!
Google BigQueryとは

Google BigQueryは、Googleが提供するフルマネージド型のデータウェアハウスサービスで、数テラバイトからペタバイト規模の大量データを超高速で分析できることが最大の特徴です。2012年のGoogle I/Oで正式にリリースされたこのサービスは、Google Cloud Platform(GCP)上で利用可能であり、Google社内で以前から使用されていたDremelという解析ツールをベースに一般ユーザー向けに提供されるようになりました。
Google BigQueryを使用することで、データ分析、データ保存、そしてGoogleが提供する様々なツールとの連携が可能になります。データ分析においては、リアルタイムでのデータ処理能力を持ち、大量のデータを格納する場所としても利用できるため、膨大なログ情報などの分析に適しています。また、PythonやAPIを介したプログラミングによるデータ処理も可能であり、高度な分析ニーズにも対応しています。
BigQueryの優れた点は、その処理速度と扱いやすさにあります。高速なデータ処理能力は、Googleが開発したカラム型データストアとツリーアーキテクチャによるもので、これにより数百万行以上のデータでも短時間で分析結果を得ることが可能です。加えて、SQLを用いたデータ分析が行えるため、データサイエンティストだけでなく、SQLの基本的な知識を持つ多くのユーザーが容易にデータ分析を行えるようになっています。
Google BigQueryの仕組み

Google BigQueryのデータ処理の速さは、特にそのカラム型データストアとツリーアーキテクチャによって実現されています。これらの技術により、数十秒で120億行のデータを処理するなど、驚異的なスピードでのデータ分析を可能にしています。
データの保存形式と処理のアーキテクチャの相乗効果で、ビッグデータの高速処理を可能にしており、これがGoogle BigQueryを他のデータウェアハウスサービスと区別する最も重要な要素となっています。
- カラム型データストア
- ツリーアーキテクチャ
それぞれ詳しく見ていきましょう。
カラム型データストア
Google BigQueryが採用しているカラム型データストアとは、データベースがデータを列単位で保存し管理する方式を指します。従来の行指向のデータベースとは異なり、カラム型では各列に対応するデータが連続して保存されます。この方式の最大の利点は、特定のクエリに対して必要なデータ列のみを読み込むことで、処理速度を大幅に向上させることができる点です。
行指向のデータベースでは、クエリを処理する際に関連する行全体が読み込まれるため、分析対象とならないデータも含めてメモリにロードされます。これに対し、カラム型データストアでは、クエリで必要とされる列のデータのみが読み込まれるため、不必要なデータの読み込みを避けることが可能です。結果、データの読み込み量が減少し、データベースのパフォーマンスが向上します。
さらに、カラム型データストアは、データの圧縮にも優れています。同じ列内のデータは同じ型のデータで構成されているため、より効率的にデータを圧縮することが可能です。これにより、ストレージの使用量を節約し、データの読み込み速度をさらに速めることができます。
カラム型データストアの特性は、特に大量のデータを効率的に分析する必要があるビッグデータの分析に適しています。Google BigQueryでは、このカラム型データストアを採用することで、数ペタバイト規模のデータセットに対しても高速なデータ分析を実現しています。
ツリーアーキテクチャ
ツリーアーキテクチャは、Google BigQueryに採用されているデータ処理の重要な仕組みです。このアーキテクチャは、クエリを効率的に実行し、大量のデータを迅速に処理するために設計されています。ツリー構造を採用することで、BigQueryは複雑なデータ分析クエリも高速に実行できるようになっています。
ツリーアーキテクチャでは、クエリの処理が階層的に管理されます。このアーキテクチャの最上位には「ルートサーバー」があり、このサーバーがクエリを受け取ります。ルートサーバーは、クエリをより小さなタスクに分割し、「中間サーバー」と呼ばれる下位のサーバー群にこれらのタスクを割り当てます。中間サーバーはさらに、これらのタスクを実行するために、「リーフサーバー」と呼ばれるさらに下位のサーバーに割り当てます。リーフサーバーは、実際にデータストレージにアクセスし、必要なデータを読み込んでクエリの処理を行います。処理結果は、ツリーの逆方向をたどって中間サーバーを経由し、最終的にルートサーバーに集約されます。ルートサーバーは、すべての結果を統合し、最終的なクエリの結果をユーザーに返します。
このツリー構造によって、BigQueryは膨大な量のデータに対するクエリを、多数のサーバーで並行して効率的に処理することが可能になります。この分散処理により、大規模なデータセットでも高速なクエリの実行速度を実現しています。
ツリーアーキテクチャの採用は、BigQueryがビッグデータの分析において非常に高いパフォーマンスを発揮する理由の一つです。データの読み込みからクエリの実行、結果の集約まで、すべてのプロセスがこの効率的なアーキテクチャによって支えられています。
Google BigQueryの用途・できること

Google BigQueryは、その強力なデータウェアハウス機能により、膨大な量のデータ解析、データのリアルタイム分析、そしてAPIを通じた様々なアプリケーションとの連携が可能な点で特に注目されています。
GMO TECHにSEOを相談する膨大な量のデータ解析
BigQueryは数テラバイトからペタバイト規模のビッグデータを扱う能力を持っています。そのカラム型データストアの採用により、不要なデータの読み込みを避け、分析に必要なデータだけを効率的に処理することができます。これにより、ビッグデータの分析を高速に実行することが可能となり、巨大なデータセットから価値あるデータを迅速に抽出できます。
データのリアルタイム分析
BigQueryの高速処理能力とフレキシブルなスケーリング機能により、リアルタイムでのデータ分析が可能です。これは、ビジネスの意思決定時や、ユーザー行動のモニタリング、さらにはセキュリティ監視など、即座に情報が必要とされる多くのシナリオにおいて極めて価値が高い機能です。
API連携(Pythonでの実行)
BigQueryは、Google Cloud PlatformのAPIを通じて、Pythonをはじめとする多様なプログラミング言語からのアクセスをサポートしています。開発者はBigQueryを自動化スクリプトやアプリケーションと簡単に統合できます。例えば、Pythonスクリプトを使用してBigQueryからデータを取得し、データ加工や分析を行い、最終的な結果を自動的にユーザーに提供するといったことが可能になります。
Google BigQueryの特徴(メリット)

Google BigQueryの特徴としては以下の4つの点が挙げられます。
- サーバーレスで専門知識が不要
- データの処理速度が高い
- 低コストで利用できる
- GA4との連携が可能
サーバーレスで専門知識が不要
BigQueryは、フルマネージド型のサービスであり、サーバーの構築や管理が不要です。これにより、ユーザーはインフラの複雑さを気にすることなく、データのアップロードや分析に集中できます。また、SQLによるデータ操作が可能で、データサイエンスやエンジニアリングの専門知識がなくても、クエリ言語で複雑なデータ分析を行うことができる点も大きなメリットです。
データの処理速度が高い
BigQueryのカラム型データストアとツリーアーキテクチャにより、膨大なデータセットに対しても高速なデータ処理を実現しています。数十億行以上のデータを数秒から数分で分析できる能力は、リアルタイムでのビジネスインテリジェンス(BI)分析や即時の意思決定を必要とするアプリケーションにとって非常に価値が高いといえるでしょう。
低コストで利用できる
BigQueryの料金モデルは、ストレージとクエリ実行の2つに大別され、使用した分だけの従量課金制です。特に注目すべきは、毎月の無料枠(ストレージでは10GBまで、クエリ実行では1TBまで)が提供される点で、小規模から中規模のプロジェクトでは、低コストでBigQueryを利用できる可能性があります。
GA4との連携が可能
BigQueryは、Google Analytics 4(GA4)と直接連携が可能で、ウェブサイトやアプリの利用データを自動的にエクスポートし、詳細な分析やカスタムレポートの作成を行うことができます。この機能により、マーケティング担当者やデータアナリストは、ユーザー行動を深く知ることが可能になり、より効果的な戦略立案やパフォーマンス改善が可能になります。
Google BigQueryの料金

Google BigQueryの料金体系は、主に「コンピューティング料金」と「ストレージ料金」の2つの要素で構成されており、そこにデータの読み込みに関する費用がプラスされます。
コンピューティング料金は、SQLクエリを実行するための料金であり、データ分析に直接関連するコストです。BigQueryの場合、毎月最初の1TBのデータ処理は無料で提供されます。1TBを超えたクエリの実行に対しては、処理されたデータ量に応じて従量課金が適用されるため、ユーザーは分析のニーズに応じて柔軟にコストを管理できます。また、プロジェクトごとにクエリのデータ量上限を設定できるため、予期せぬ高額な料金が発生するリスクを減らすことができます。
ストレージ料金は、BigQueryに保存されたデータの量に基づきます。ユーザーはデータをBigQueryにアップロードして保存するため、このデータの量に応じたストレージのコストが発生します。BigQueryは毎月10GBまでのストレージを無料で提供し、それを超える使用量に対してはGBあたりの料金が発生します。さらに、90日間アクセスされなかったデータについては、長期保存の料金が適用されます。
BigQueryでは、データの読み込み自体に直接費用はかかりません。しかし、ストリーミング挿入のように、リアルタイムでデータをBigQueryに挿入する機能を使用する場合には追加料金が発生します。この料金は、挿入されたデータの量に基づいて計算され、データを即座に分析可能な状態で保持するためのコストです。
このように、BigQueryの料金体系は、データをどれだけ分析し、保存するかによっており、ユーザーは自身の分析ニーズと予算に応じて柔軟にサービスを利用できます。また、無料枠が提供されているため、小規模なプロジェクトや初期段階のデータ分析では、低コストで高度な分析を実行することが可能になります。
| 要素 | 対象 | 料金 | 備考 |
|---|---|---|---|
| コンピューティング料金 | オンデマンドクエリ | $7.5 per TiB | 月1TBまで無料 |
| Standard エディション スロット | $0.051 / slot hour | 最小課金時間は1分 | |
| Enterprise エディション スロット | 課金:$0.0765 / slot hour
1年契約:$0.0612 / slot hour 3年契約:$0.0459 / slot hour |
課金の場合、最小課金時間は1分 | |
| Enterprise Plus エディション スロット | 課金:$0.1275 / slot hour
1年契約:$0.102 / slot hour 3年契約:$0.0765 / slot hour |
課金の場合、最小課金時間は1分 | |
| ストレージ料金 | アクティブなローカル ストレージ | $0.023 per GiB per month | 月10GBまで無料 |
| 長期の論理ストレージ | $0.016 per GiB per month | 月10GBまで無料 | |
| アクティブな物理ストレージ | $0.052 per GiB per month | 月10GBまで無料 | |
| 長期の物理ストレージ | $0.026 per GiB per month | 月10GBまで無料 | |
| データ読み込み | ストリーミング挿入 | $0.012 per 200 MB | 正常に挿入された行が課金対象
最小サイズは1KB |
| BigQuery Storage Write API | $0.03 per 1 GiB | 月2TBまで無料 |
Google BigQueryの使い方
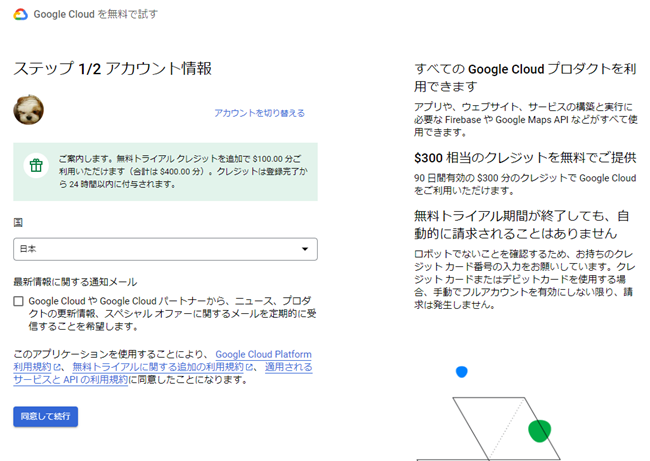
- 公式サイトにアクセスして「BigQueryの無料トライアル」を選択し、アカウント情報の登録を行います。
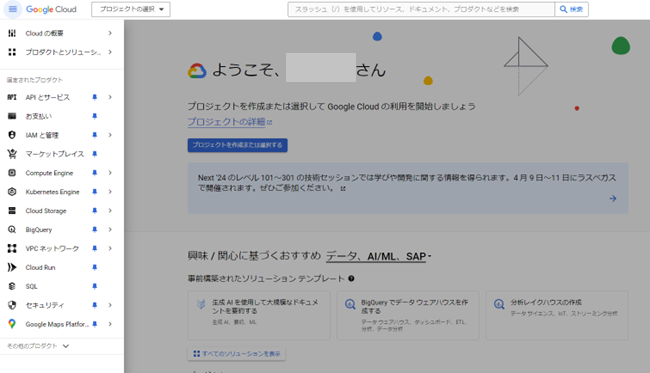
- Google Cloud Platform(GCP)のナビゲーションメニューから「BigQuery」を選択します
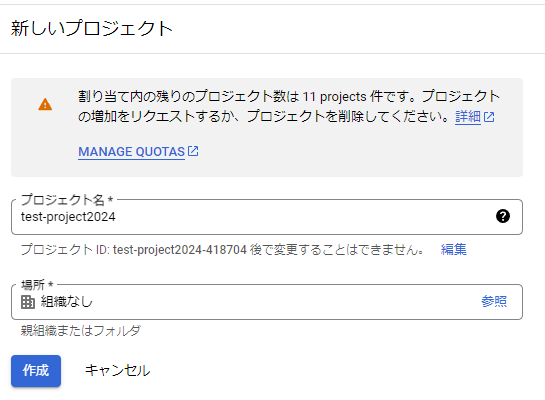
- 「新しいプロジェクト」を選択してプロジェクトを作成します
- 「エクスプローラ」から「データセットを作成」を選択します
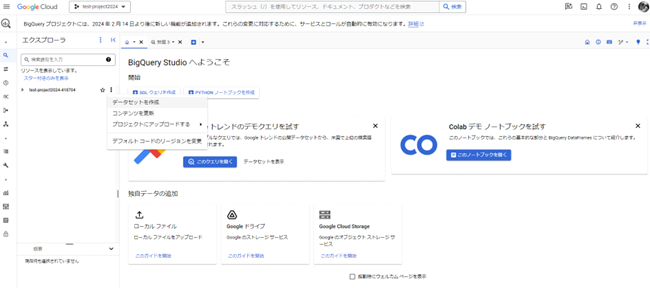
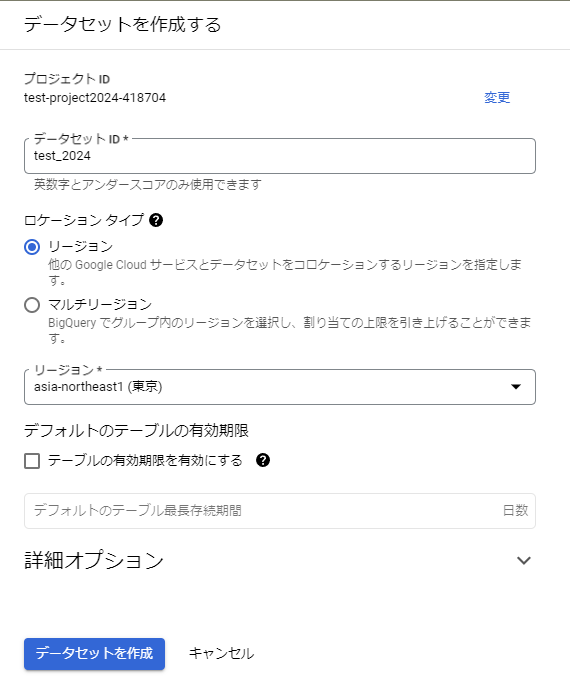
- データセットIDやロケーションタイプなど設定してから「データセットを作成」を選択します
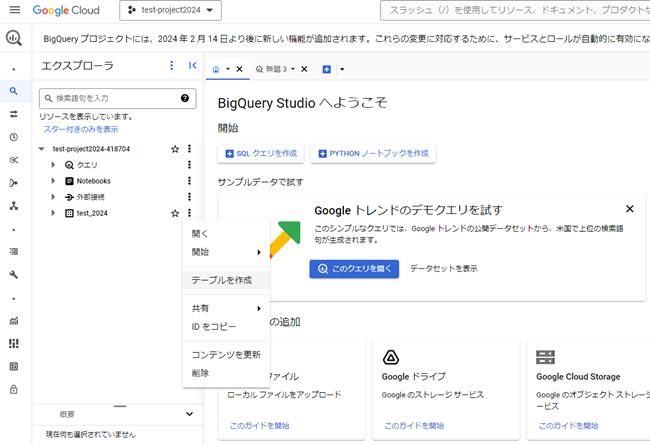
- 「アクションを表示」から「テーブルを作成」を選択する
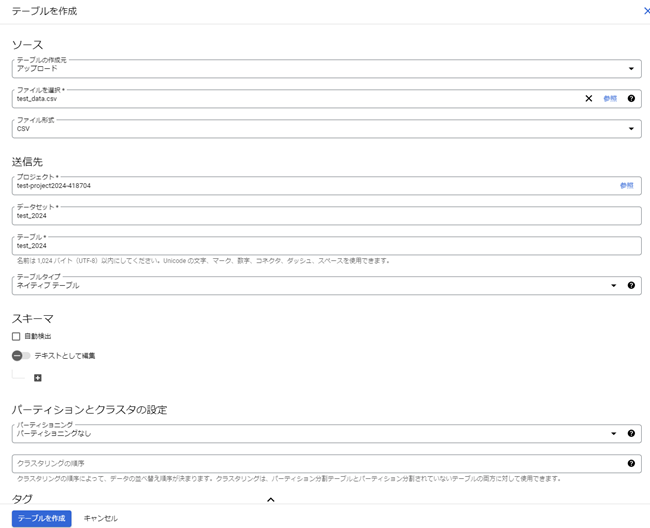
- テーブルの作成元やファイル、データ名を設定してから「テーブルを作成」を選択します
- 「プレビュー」を選択して読み込んだデータを確認します
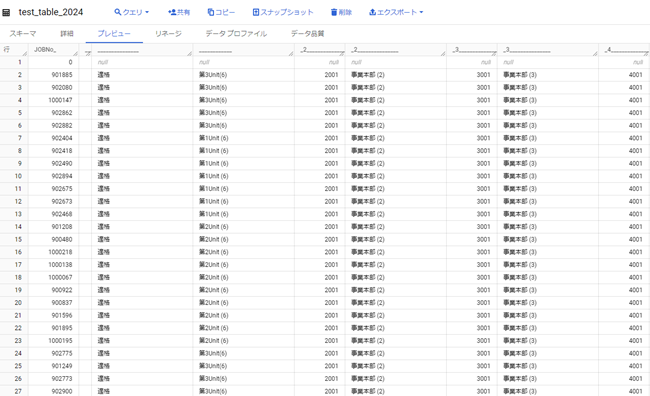
- 「クエリ」を選択して読み込んだデータを解析します
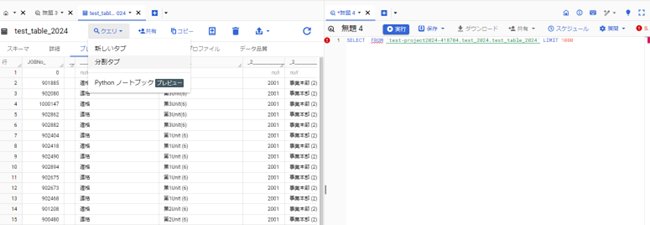
Google BigQueryの活用事例

BigQueryは日本国内の企業でも使われており、またその導入企業は様々な分野にわたります。いくつかの導入事例を紹介しましょう。
- 株式会社 LIXIL
- 株式会社ぐるなび
- JapanTaxi株式会社
- 日本テレビ放送網株式会社
- 株式会社MonotaRO
株式会社 LIXIL
株式会社LIXILは、BigQueryを中心としたデータ活用基盤「LIXIL Data Platform」(LDP)を構築しています。このプラットフォームは、専門知識がない従業員でもデータを扱えるようにすることを目指し、「データ活用の民主化」を推進しています。Google Cloudの各種機能を活用し、グローバルで運用可能なデータ連携アーキテクチャを実現しています。LDPは「Big Data Core」と「Data Analysis」の2つのコンポーネントで構成されており、SAPやメインフレーム、Webアプリケーションサーバー、生産設備、IoTのログデータに至るまで、多岐にわたるシステムからのデータが日々蓄積され、LIXILの標準データ基盤として活用されています。
BigQueryを中心にしたLDPの導入により、株式会社LIXILでは以下のような成果を上げています。
- データ活用の加速:誰もが手軽にLDPに蓄積されたデータを検索できるようになり、データの活用が加速しました。
- 大規模なデータ分析の実現:従来では不可能だった大規模なデータ分析が可能になり、課題解決が促進されました。
- 開発・運用の効率化:マネージドサービスを中心にシステムを構築することで、少ない人員での開発・運用を実現しました。
- パフォーマンスの向上と運用コストの低減:LDPのアーキテクチャは利用者が増えてもパフォーマンスが下がらず、運用コストも上がらない設計になっています。
- 営業プロセスの効率化:LDPを活用することで、高速な処理が可能になり、従来見えなかった営業担当者個別の詳細な分析を実現し、営業プロセスの改善にも取り組む予定です。
- 製品パーツの影響分析の効率化:特定のパーツが生産終了になることの影響を洗い出す作業で、処理時間が大幅に短縮され、商品開発部門の工数を削減しました。
LIXILは、BigQueryを軸とするこの先進的なデータ活用基盤を通じて、ビジネスプロセスの効率化、意思決定の迅速化、そしてデータドリブンな組織文化の実現を目指しています。
参考:Google Cloud|LIXIL:BigQuery を中心としたデータ活用基盤 LIXIL Data Platform を構築、”データ活用の民主化” を推進
株式会社ぐるなび
株式会社ぐるなびでは、Google Cloudを基盤にBigQueryを中心としたデータ分析基盤を刷新し、ユーザーの利便性向上と飲食店とのマッチング強化に取り組んでいます。特に、データ分析基盤の刷新を通じて、レコメンド機能などで情報をパーソナライズ化し、ユーザーに合った選択肢を提供することが目的です。このプロセスにおいて、BigQueryの高速なクエリレスポンス、スケーラビリティ、及びGoogleスライドやスプレッドシートとの連携により、ビジネス部門へのデータ提供を加速できることが大きなメリットとして挙げられています。
BigQueryとCloud Composerの導入により、株式会社ぐるなびは以下の成果を達成しました。
- 運用工数の大幅削減:Cloud Composerの導入により、ジョブ失敗時の迅速な原因究明が可能になり、作業工数が大幅に削減されました。また、ETLに関するランニングコストを約50%削減し、作業の効率化を実現しました。
- コスト削減:マネージドサービスであるCloud Composerは、Googleアカウントがあれば誰でも使用可能で、環境の構築と削除が容易です。これにより、最小限のスペックから始めて、必要に応じて柔軟に拡張でき、コストパフォーマンスを大幅に改善しました。
- データ活用の迅速化:新しいデータ分析基盤はストレージサービスを利用したデータレイクとBigQueryで構成され、Cloud Storageを経由してDataLake層に格納されたデータを迅速に加工してDWH、DataMartの各層を作成し、Googleスプレッドシート、Lookerによる可視化やアドホッククエリによる分析に活用しています。
さらに、ぐるなびはBigQueryを利用することで、インデックスを考慮せずとも高速に結果を得られること、複雑なクエリも迅速に処理できること、他社のクラウドオブジェクトストレージからCloud Storageへのデータ転送が簡単かつ高速に行える点をメリットとして挙げています。
これにより、オンプレミスを廃止し、すべてをクラウドによる運用に移行する計画を進めており、運用監視の効率化、BigQuery Omniによるマルチクラウド管理、Lookerを活用した全体最適化を目指しています。
参考:Google Cloud|ぐるなび:BigQuery を中心にデータ収集からデータの可視化や活用まで Google Cloud でデータ分析基盤を刷新
JapanTaxi株式会社
JapanTaxi株式会社では、BigQueryを中心にしたデータ分析基盤を利用して、タクシー配車アプリ『JapanTaxi』を支えています。このアプリは、スマートフォン上でタクシーの予約やキャッシュレス決済、多言語対応など、幅広い機能を提供し、ビジネスパーソンから国内外の旅行者まで、多くのユーザーに利用されています。JapanTaxiは、アプリから得られるビッグデータをBigQueryに集約し、ユーザビリティの向上や業務効率の改善を目指すためのデータ分析を行っています。具体的には、数十秒おきに送られてくるタクシーの位置情報や、アプリからの注文情報(位置情報、利用時間、ユーザー情報など)など、サービスにまつわるさまざまなデータを高速かつ効率的に運用しています。
JapanTaxi株式会社がBigQueryを活用することで得られた主な成果は、以下のとおりです。
- 高速データ処理:BigQueryを採用したことで、アドホック分析時の待ち時間が大幅に短縮され、従来数時間かかっていたデータ処理が数秒で可能になりました。これにより、分析チームは本質的な分析作業により多くの時間を割くことができるようになりました。
- 運用の効率化:BigQueryのフルマネージドな特性により、大規模分散処理システムのメンテナンスにかかる労力を削減しました。結果として、少人数のチームでデータ分析基盤の運用が可能となりました。
- 利用者の拡大:BigQueryへの移行により、以前はデータ分析基盤にアクセスできたのは一部のエンジニアのみでしたが、多くの社員にデータ分析ツールを開放し、非エンジニアもデータ分析に直接関われるようになりました。これは、ビジネスのスピード感を大幅に高める成果として評価されています。
- GISの活用:BigQuery GISを活用することで、タクシーの位置情報や注文データを地理的座標情報として直接BigQuery上でデータ集計が可能になり、営業区域などを意識したデータ提供が容易になりました。
これらの成果により、JapanTaxi株式会社は、サービスのユーザビリティ向上と業務効率の改善を実現しており、データ分析を通じてビジネスの迅速な意思決定をサポートしています。
今後もAIサービスの活用を進め、非構造化データの分析や予測モデルの自動化を目指していく計画です。
参考:Google Cloud|JapanTaxi株式会社:BigQuery を活用して、国内最大級のタクシー配車アプリ『JapanTaxi』を支えるデータ分析基盤を構築
日本テレビ放送網株式会社
日本テレビ放送網株式会社では、サイロ化したデータを統合する基盤としてGoogle Cloudを採用し、その中心にBigQueryを配置しています。データ基盤の目的は、番組や広告の価値向上、迅速な事業判断、事業効率化などで、編成部、宣伝部、営業部、報道部など複数の部門で利用されています。BigQueryは、ビッグデータ解析を高いコストパフォーマンスで実現するため選ばれました。また、Googleアナリティクス360やGoogleアドマネージャーなどのツールとの連携も大きな利点です。具体的には、番組や広告に関するビッグデータをBigQueryに集約し、Cloud AutoMLやVision APIなどを使って解析しています。
日本テレビはBigQueryを採用することで、以下の成果を達成しています。
- インフラコストの大幅削減:Google Cloudのフルマネージドサービスの恩恵により、インフラコストを大幅に削減しました。
- 解析の効率化:AutoMLを用いた解析により、データサイエンティストの作業が効率化され、「データサイエンティストの仕事がなくなる日が来るかもしれない」とまで言われるほどです。
- ビジネスサイドの担当者による機械学習の活用:高度な専門知識がないビジネス側の担当者でも、比較的簡単に機械学習を活用できるようになりました。
今後の展望として、日本テレビはGoogle Cloudによるデータ基盤を、社内のあらゆるデータを解析できる統合データ基盤に成長させる計画を持っています。これには、デジタル領域から始め、イントラデータの解析、最終的にはテレビの視聴率データの分析までを含む全方位的なアプローチが含まれます。
また、Dialogflowを使用して知りたい情報を簡単に検索できる環境の構築や、Data Catalogをメタデータ管理に使用するなど、更なるデータ活用の拡大を目指しています。
参考:Google Cloud|日本テレビ:サイロ化したデータを統合するための基盤に BigQuery を採用。トレーニングで Google Cloud を体系的に理解
株式会社MonotaRO
株式会社MonotaROは、自らを「データドリブンカンパニー」と定義し、早い段階からデータを活用したデジタルマーケティングを実施してきました。2017年にデータ分析基盤をBigQueryに移行し、それまでオンプレミス環境で取り扱いが難しくなっていた膨大なデータの管理と分析を可能にしました。BigQueryの導入は、社内のさまざまなデータを集約し、新しい分析試みを実施することを目的としています。具体的には、ウェブログと受注データを紐付けて分析するなど、従来では不可能だった分析が行えるようになりました。
BigQueryの導入により、株式会社MonotaROは以下の成果を達成しました。
- データの集約:総計100億レコードに及ぶ社内のあらゆるデータをBigQueryに集約することができました。これにより、以前は不可能だった新しい分析試みが可能になりました。
- 処理速度の向上:BigQueryの高速性により、以前は一日かかっていた処理が数十分で完了するようになりました。これにより、重いバッチ処理をデイリーで実行し、精度の高い情報に基づいた改善を行うことが可能になりました。
- データ分析を行うメンバーの増加:BigQueryを使いたいというメンバーが増え、データ分析を行う人数が4倍になりました。これは、非ITエンジニアでもデータポータルなどのツールを通じて容易にデータ分析・可視化を行えるようになったためです。
さらに、BigQuery導入後、扱えるデータ量が10倍に増加し、自動で生成される分析レポートの数も10倍に増加しました。データ分析を行うメンバーの数は4倍に増え、社内でのデータ活用文化が大きく進展しました。
これまでは限られたアナリストに依頼する必要があったデータ分析が、多くの社員によって直接行えるようになり、データドリブンなPDCAが業務改善を加速させています。
参考:Google Cloud|株式会社MonotaRO:BigQuery を駆使した新しいデータ分析基盤構築で、全社的にさらなるデータ活用を推進
まとめ
BigQueryは、大量のデータを短時間で分析することが可能な強力なデータウェアハウスサービスです。サーバーレスで利用でき、コストも比較的抑えられるため、企業のデータ分析基盤として最適です。また、GA4との連携も可能で、マーケティングデータの分析にも役立ちます。これからデータを活用してビジネスの洞察を深めたいと考えているWebマーケティング担当者の方は、ぜひBigQueryの利用を検討してみてください。
- SEO対策でビジネスを加速させる

-
SEO対策でこんな思い込みしていませんか?
- 大きいキーワードボリュームが取れないと売上が上がらない・・
- コンサルに頼んでもなかなか改善しない
- SEOはコンテンツさえ良ければ上がる
大事なのは自社にあったビジネス設計です。
御社の課題解決に直結するSEO施策をご提案します
- プロフィール
-

-
GMO TECH株式会社

- 2012年より一貫して検索エンジン領域のコンサルティング業務に従事。 2017年にGMO TECH社に参画。営業組織の構築、新商材開発、マーケティング部門立ち上げをおこなう。 現在、MEOコンサルティング、SEOコンサルティング、運用型広告などSEM領域全体を統括し、 お客様の期待を超える価値提供を行うため日々、組織運営・グロースに奔走している。
-
GMO TECH株式会社