


クローラーとは?意味や種類・SEOにおける重要性や対策方法をわかりやすく解説

ただし、ただ巡回しているわけではありません。「検索順位を決める要素を収集する」という重要な役目を担っています。
当然、「検索順位を決める要素」という点で、SEOにおいても無視できない存在です。
本記事では、クローラーの仕組みやSEOにおける重要性、対策方法について解説していきます。
クローラーとは
クローラーとは、インターネット上に存在するサイトを巡回し、「検索順位を決める要素を収集する」ロボットプログラムのことです。
クローラーという名前はインターネットの空間を這い回る(クロール:crawling)ことから名付けられました。
Google、Bingといった検索サイトを提供する企業は独自でクローラーを開発・運営しており、そのほとんどが「ロボット型検索エンジン」を組み込んでいます。
ロボット型検索エンジンは、自動的にウェブ上の情報を収集、キーワードごとにデータベース化します。
そして、ユーザーが検索したワード(クエリ)に対して適切だと思われるページを検索結果画面に返す仕組みです。
以前は人間が手動でページをカテゴリー分けする「ディレクトリ型」と呼ばれる検索エンジンが主流でしたが、インターネット利用率やウェブサイトの情報量が増加したことで人力での対応が難しくなり、現在はロボット型が主流になっています。
クローラーは検索エンジンの仕組みを知る上で重要なものです。
もっと言えば、クローラーの仕組みを理解すれば検索エンジンについて理解できたといってもよいでしょう。
Googleにおけるクローラーの仕組み
クローラーは、前述の通りロボット型検索エンジンがWebサイトを巡回する工程で機能するロボットです。
クローラーがWebサイトを巡回する工程は以下3つに分けられます。
- クローリング(crawling)・パーシング(parsing)
- インデックス
- クエリプロセス
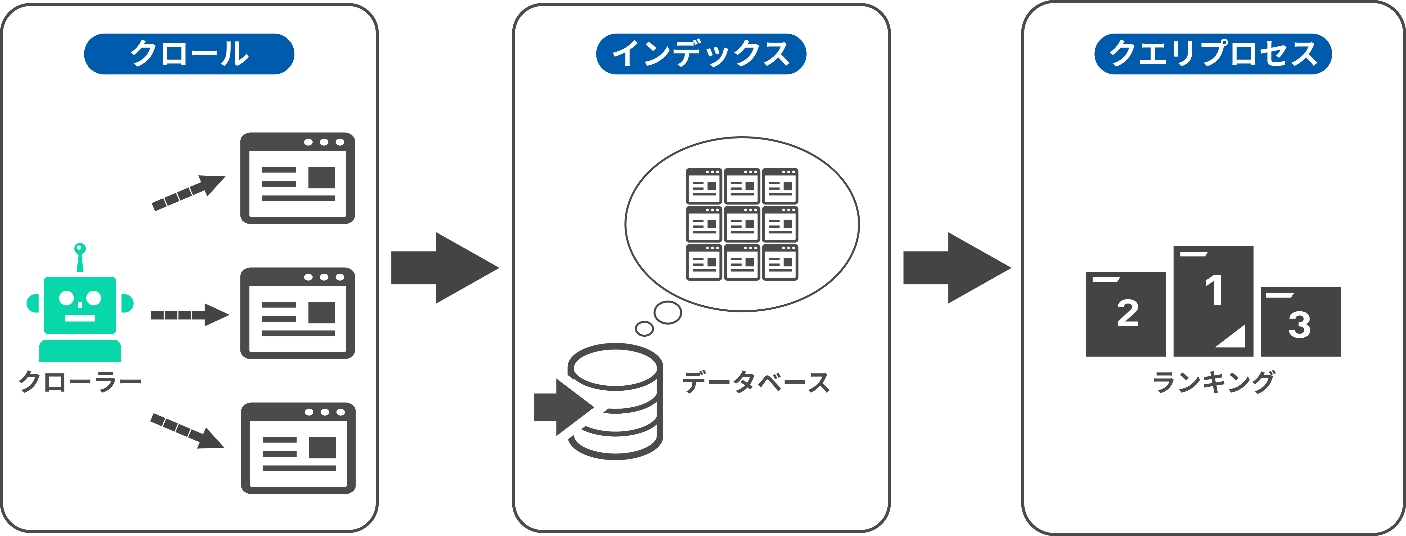
「クロール」の基本的な動きは、「Webサイトの巡回=クローリング(crawling)」と「パーシング(parsing)」に分けられます。
最初に「クローリング」の工程で、クローラーがインターネット空間にあるWebサイトを自動的に巡回していきます。
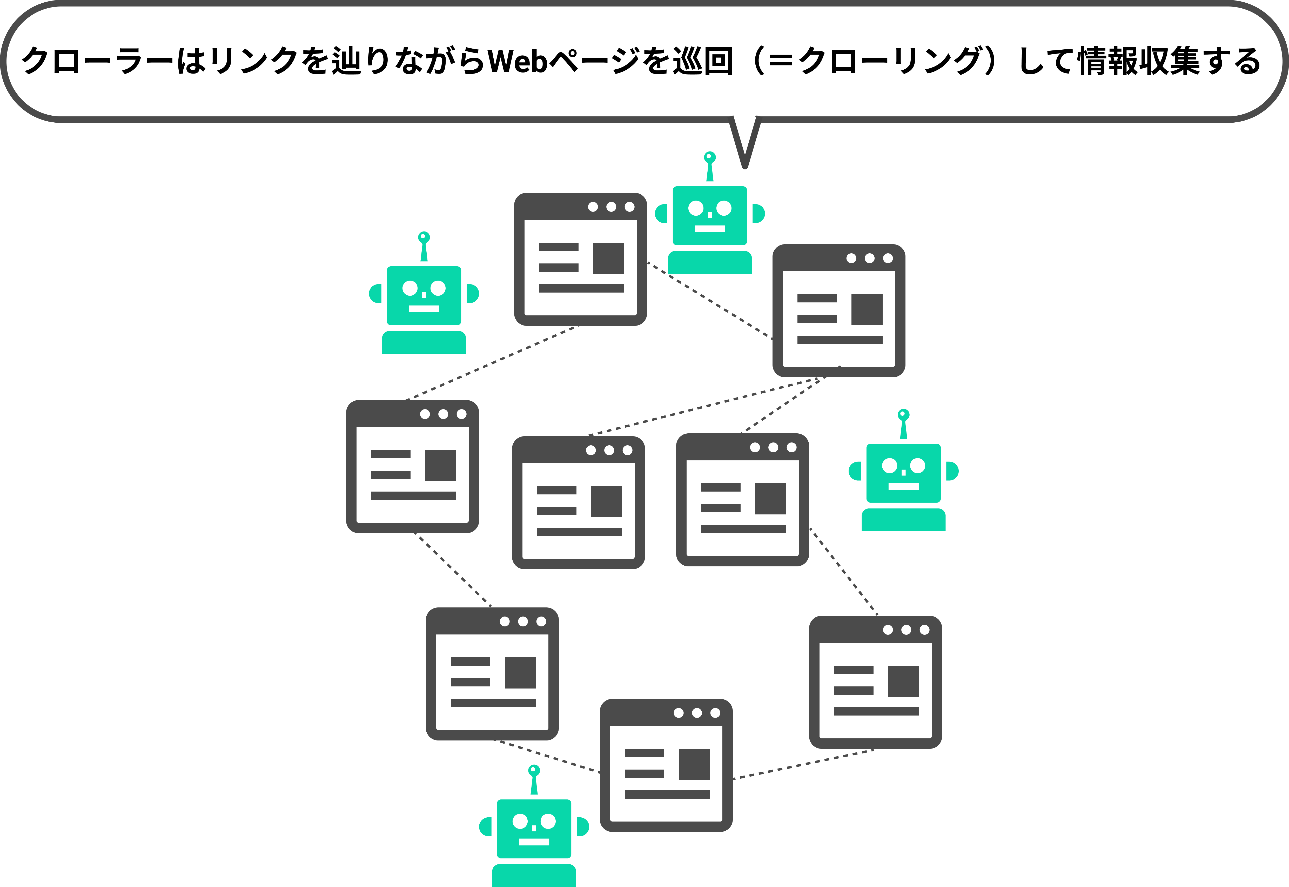
図のように、クローラーは、蜘蛛の巣のように張り巡らされたリンクをたどってページを巡回することから、「スパイダー(蜘蛛)」と呼ばれたりもします。
ページに辿り着いたクローラーは、そのページを解析します。
この解析の工程が「パーシング(parsing)」であり、クローラーはページについて情報収集していきます。
解析、情報収集を終えると、クローラーはデータをランキング要因(=アルゴリズム)にとってわかりやすい形に変換し、検索エンジンのデータベースに登録していきます。
この「登録」の工程が「インデックス」です。
「クローラーが集めた情報を解析して検索エンジンのデータベースに登録する」、その過程で新しいリンクを見つけたら、更にその先のページへ遷移し、リンク先ページの情報を解析・登録…といった形でインデックスを繰り返してきます。
情報をインデックスするデータベースは自室の本棚のようなものと考えるとよいでしょう。
書店や図書館で購入したり、借りてきたりした本を本棚にしまっていつでも手に取れるように整理しておくようなイメージです。

最後に「クエリプロセス」の工程です。
インデックスされた情報をもとに、検索クエリ(ユーザーが検索エンジンの検索窓に入力するワード)によってページがランク付けされ、検索結果に表示されます。
ランク付けの決定要因は200以上の項目で構成される「アルゴリズム」というプログラムになります。
アルゴリズムの精度や項目は日々向上、アップデートされています。
そのため、SEOではこのアルゴリズムの最新情報も追いかける必要があります。
クローラーは上記3つの工程を繰り返して新規情報を収集しています。まずはクローラーにいち早くインデックスしてもらうことが検索結果に表示されるために重要です。
SEOにおけるクローラーの重要性
検索結果はクローラーが収集した情報をもとに形成されたデータベースをもとに作られます。
そのため、クローラーはSEOにおいても重要な役割を果たしています。
どんなに内容が素晴らしいコンテンツであってもクローラーに認知されない限り、検索結果に表示されませんし、ユーザーに閲覧してもらうこともできません。
せっかく作った自社サイトが検索結果に表示されないのはもったいないですし、集客に繋げることも難しくなってしまいます。
また、検索エンジンは、「ユーザーにとって有益な情報」を提供するためのデータベース構築を重要視しています。
クローラーは一度のクローリングでサイト内の全ての情報を解析できるわけではなく、複数回に分けて訪れます。
そのため、訪れるたびに最新情報が更新されていたり、常に正確な情報が掲載されている有益なサイトは、何度もクローラーが訪れ、結果としてコンテンツがきちんと評価されるようになり、順位の向上も見込めるのです。
このように、Webサイト運営者にとって、まずはクローラーに自社サイトを見つけてもらうこと、そしてコンテンツ内容を高く評価してもらうための施策がSEO上重要になります。
クローラーの対象ファイル
クローラーの巡回対象となるのは、下記のようなファイルです。
- HTMLファイル
- CSSファイル
- テキストファイル
- JavaScriptファイル
- 画像ファイル
- PDFファイル
- FLASHフィアル

人間がブラウザ上で閲覧できる情報と同じものを収集しています。
人間が利用するブラウザの通信プロトコル(通信規格)は「HTTP/HTTPS」なので、クローラーも「HTTP/HTTPS」の情報をクローリングできます。
クローラーの種類
クローラーはGoogle以外にも存在します。代表的なクローラーは下記の通りです。
- Googlebot
- Bingbot
- Yahoo Slurp
- Baiduspider
- Yetibot
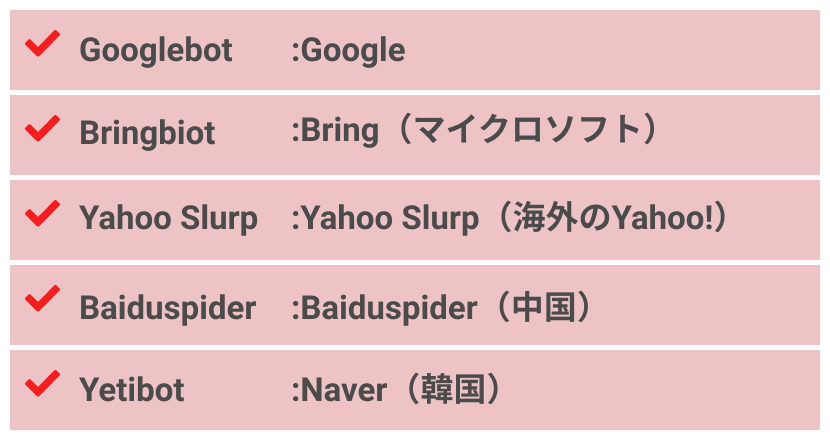
なお、日本国内でSEOをおこなう際は、Googlebotを重視することになります。Googleの国内シェアが7割以上になるためです。
また、Googleのクローラーは一種類ではなく、PC用やスマホ用、画像用、CSS用など分野ごとに手分けしてして細かくクローリングしています。
クローラーの種類の中にYahoo! JAPANがありませんが、これはYahoo!も2011年からGoogleの検索エンジンを採用しているためです。
クローラーの巡回を促す対策
クローラーの巡回しやすさを表す指標としてクローラビリティがあります。
クローラビリティを向上させるには以下の5つのポイントがあります。
- クロールをリクエストする
- URLを見直す
- XMLサイトマップを作成する
- robots.txtを設置する
- 内部リンクを最適化する
- リンクが切れているWebページを減らす
- パンくずリストを設定する
一般的に上記の対策についてはクローラビリティを向上させるために最低限行っておきたい点です。
クロールをリクエストする
Googleの検索エンジンに関しては、クロールをリクエストすることが可能です。
新しくページを追加したり、ページを更新したりした際はリクエストをおこないましょう。
まずはGoogleサーチコンソールへの登録をおこなう必要がありますので、詳細は下記の記事をご覧ください。
Googleサーチコンソールの「インデックス登録リクエスト」を利用してGoogleにクロールを促します。
XMLマップ送信と同様にページの所在をクローラーに伝えることができる機能で、優先的にクローリングしてもらえます。
クロールリクエストの方法
サーチコンソール左サイドのメニューにある「URL検査」をクリックします。
すると上部の入力欄が展開しますので、任意のURLを入力しましょう。

検査したいURLを入力すると下図のような画面に遷移します。
下記は検査URLがインデックス登録されていなかった場合のキャプチャです。

「インデックス登録をリクエスト」をクリックするとリクエストが完了します。
URLを見直す
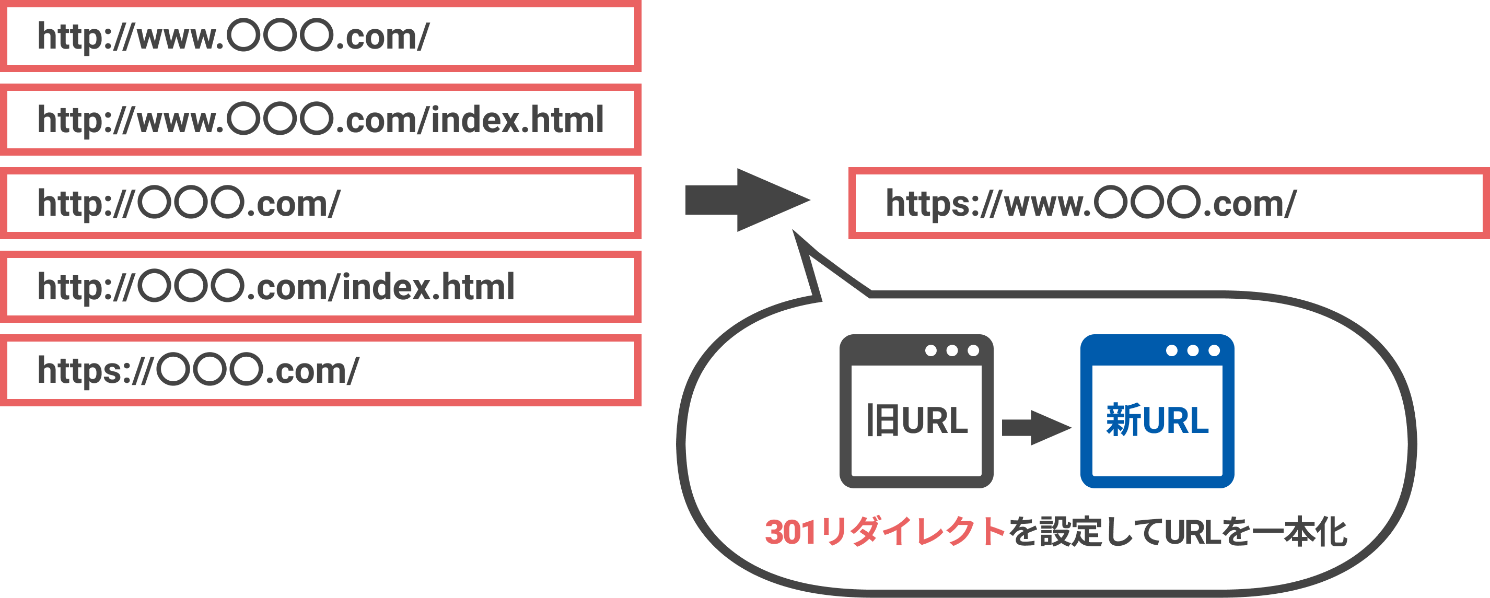
自社サイトのURLがどんな状況になっているか、確認したことはありますか?
よくある例として、「WWW.」が含まれるURLと含まれないURLの両方がWebサイトに存在しているケースがあります。
ユーザーの視点では特に問題ないように感じられますが、クローラーは、“同じ情報を持つそれぞれのURL”を巡回することになり、無駄なクロールが発生することになります。
これを「クロールバジェットの浪費」と言ったりします。
1度にクロールできる上限がある中で、無駄なクロールをさせるのはもったいないですよね。
「URLの見直し」の目的は、このような「クロールする必要のないページ」を見つけ、無駄を省くことでクローリングしてもらいやすい環境を整えることにあります。
また、重複する内容を持つURLは、SEO上のリスクもあることを覚えておきましょう。
クローラーはURLを元にページを判断しているため、同じ内容を掲載しているにも関わらずURLが異なるページは「重複コンテンツ」と判断される恐れがあります。
重複コンテンツはペナルティの対象であり、放置していると順位評価を落とすだけでなく、インデックス削除による非表示といったSEO上のリスクがあります。
このような自体を避けるためにも、URLは統一しておきましょう。
URL見直しの具体的な方法(301リダイレクト)
具体的な方法は、「301リダイレクト」というHTTPステータスコードの実装です。
たとえば、「https://www.〇〇〇.jp」から「https://〇〇〇.jp」のURLに301リダイレクトを実装して、「wwwあり」「wwwなし」を統一(正規化)します。
すると、「https://〇〇〇.jp」のURLが正規URL(一番重要なページ)としてGoogleに認識されます。
URLを統一する前は「wwwあり」「wwwなし」両方のURLがクローリングされていましたが、統一後は、「wwwあり」のURLはクローリングされないため、無駄を削減することができます。
301リダイレクトについて知りたい方は、下記の記事で詳しく解説していますのでご参照ください。
また、「301リダイレクト」の他に「canonicalタグ」で処理する方法もあります。
「canonicalタグ」については下記で解説しております。
ただし、複数の異なるURLで同一ページにアクセスしてしまう場合は、301リダイレクトを優先することをGoogleの公式サイトでも言及しています。
サーバー側での 301リダイレクトは、ユーザーや検索エンジンを正しいページに確実に誘導するのに最適な方法です。ステータス コード 301は、ページが別の場所に完全に移転したことを意味します。
引用元:重複コンテンツの作成を避ける(Google)
なお、以前は「Google Search Console」で重複ページを解消することができましたが、2019年に「Googleサーチコンソール」がリニューアルされたため、同様の処理ができなくなりました。
したがって、現在はサイト内で301リダイレクトの実装をおこなうことになります。
XMLサイトマップを作成する

XMLサイトマップとは、サイト内のページ構成やコンテンツをいち早く検索エンジンに理解してもらうため、サイト全体を一覧できる設計図のようなものです。
基本的に適切に内部リンクが張り巡らされているサイトであれば、クローラーはほとんどのページをクローリングしますが、クローラーがインターネット空間にある膨大なページを理解するには時間が必要です。
そこで、XMLサイトマップを作成してサーバーに設置し、Googleサーチコンソールを使ってサイトマップを送信します。
前述の通り、Googlebotはページに張られているリンクを辿り(クローリング)、ページの情報を収集していきます。
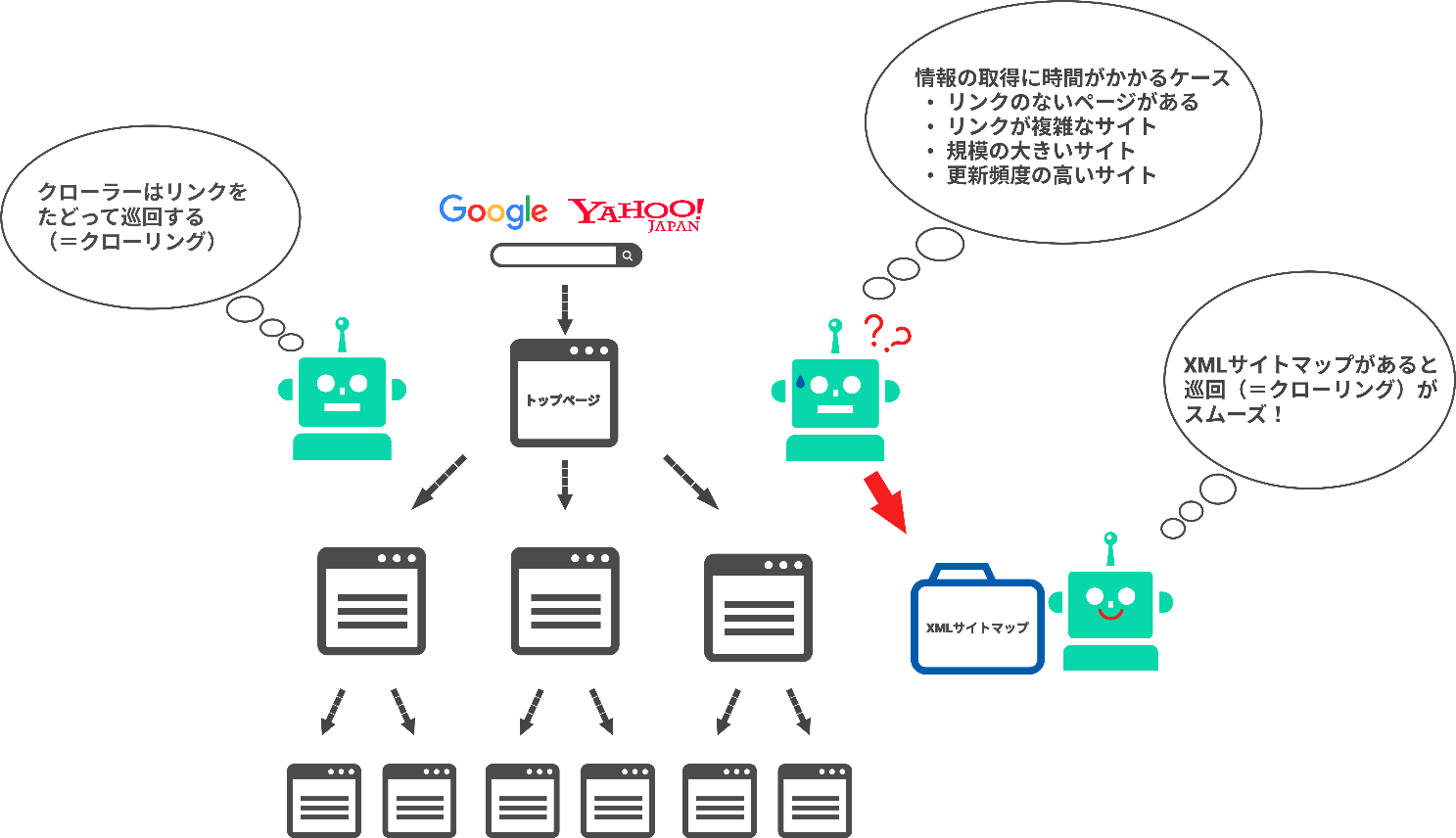
XMLマップがあれば、優先的にクローリングするページをクローラーに伝えることができます。
XMLサイトマップはGoogleサーチコンソールから送信できます。
送信方法については「2021年版|Googleサーチコンソールの使い方(登録・設定方法も解説)」を参照してください。
XMLサイトマップの作成は手動でコードを記述することもできますが、知識がない場合は自動作成ツールを使うとよいでしょう。
自動作成ツールの「sitemap.xml Editor」は、無料で利用できます。
詳しい操作は公式サイトを参照してください。
特に、以下のような条件に合致するサイトは、XMLマップの作成・送信をおすすめします。
- サイトのサイズが大きい(500ページ以上)
- サイト内部のリンクができていない
- 外部からのリンクが少ない
- 画像や動画などのコンテンツが多数ある
robots.txtを設置する
robots.txtにはサイトマップのURLを記述することができます。
省略も可能とされている項目ですが、記述することで指定したクローラーが早くサイトを巡回してくれる可能性があります。
自社サイトのクローラビリティを高めるためにも記述しておきましょう。
詳しくは下記の記事で解説していますので、併せてご確認ください。
内部リンクを最適化する
繰り返しお伝えしてきたように、クローラーはリンクを辿ってサイト内を巡回します。
よって、内部リンクが張り巡らされているサイトは、それだけ多くのページへクローラーがたどり着きやすくなります。
この記事でも要所で関連するコンテンツへの内部リンクを掲載してきましたので、振り返ってみてください。
また、内部リンクはSEOにおいても重要な施策です。
関連するコンテンツをリンクで繋ぐことによって、サイトの網羅性を高めたり、特定のトピックにおける関連性を強めたりすることが可能になります。
設置するリンクはユーザーの興味を惹く関連コンテンツで問題ありません。
ただし、Googleの検索エンジンはhref 属性が指定された<a>タグしかクロールできないため、必ず<a>タグを用いたリンクを設置するようにしましょう。
SEOと内部リンクについては下記の記事で詳しく解説しています。
リンクが切れているWebページを減らす
リンク切れとはURLの変更やサイトの閉鎖、削除などを理由により、リンク先にアクセスできない状態を指します。リンク切れは以下の点が懸念されるため注意すべきです。
- クローラビリティの低下
- ユーザビリティの低下
クローラーにとって、クローリングできないページが散乱するサイトはクローラビリティがよい状態とは言えません。
またユーザーにとっても、リンク先のページがリンク切れで閲覧できない状態になっていればストレスがかかります。
サイトのページ数が増えれば触れるほど、リンク切れが発生するリスクは高くなりますが、クローラビリティ、ユーザビリティともに弊害が大きいものですので、できる限り回避しましょう。
また、リンクが切れているページに遷移すると「404エラー」が表示されます。

404エラーは直接的に検索順位の要因にはなりませんが、このような表示が何度も出るような状態ではユーザーがサイトを離脱するリスクが高まります。
リンク切れのページは、Googleサーチコンソールから確認可能ですので、今一度チェックしてみましょう。
パンくずリストを設定する
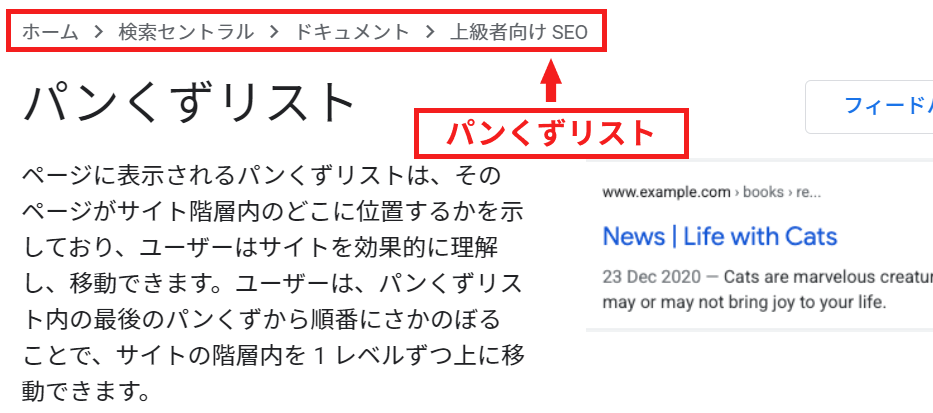
パンくずリスト(英:Breadcrumb List)は、現在見ているページがサイト内のどの位置にあるかを階層構造で示したリンク付きのリストのことです。
それぞれ上位ページの箇所にはリンクが貼られており、クリックすると上位階層に瞬時に戻ることもできます。
クローラーはリンクを辿っていくため、パンくずリストを設置することで回遊率の向上が見込めます。
また、Webサイト内のどの階層にいるのかを認識しやすくなるため、「Googleにとって理解しやすいサイト」になります。
加えて、パンくずリストはサイトにアクセスしたユーザーにとっても、「自分は今どのページを閲覧しているのか」が視覚的にわかりやすく表示されるため、ユーザビリティの向上も見込めます。
パンくずリストについては下記の記事でも詳しく解説していますので、併せてご確認ください。
クローラーを拒否してWebサイトをクローリングさせない方法
クローラーに巡回を促すだけでなく、逆に巡回をブロックすることもできます。
たとえば、サイトのテスト表示やサーバーに負荷をかけるファイル(画像、動画など)など、検索結果に表示させる必要性がない、あるいは意図的に表示させたくないページに対してブロック制御の指示を出すことができます。
クロール不要なページを指定して無駄なクロールが発生しないようコントロールすることで、クローラーにWebサイト内でより重要度の高いページへ効率的かつ優先的に巡回してもらうことができます。
ブロック方法は、robots.txt(ロボットテキスト)と呼ばれるファイルの利用が有効です。robots.txtにブロックを指示する構文を記述しサイトにアップロードして実行できます。
具体的な記述やアップロードの設定方法については下記の記事を参照してください。
また、Googleの公式ページを参考にすると良いでしょう。
クローラーがWebサイトを巡回したか確認する方法
クローラーがWebサイトを巡回したか確認するには以下の2つの方法があります。
- 「site:」で検索する
- Googleサーチコンソールで確認する
「site:」で検索する
検索エンジンの検索窓で、URLやドメイン名の前に「site:」を入れて検索すると、サイトのインデックスの状況を簡易的に確認できます。
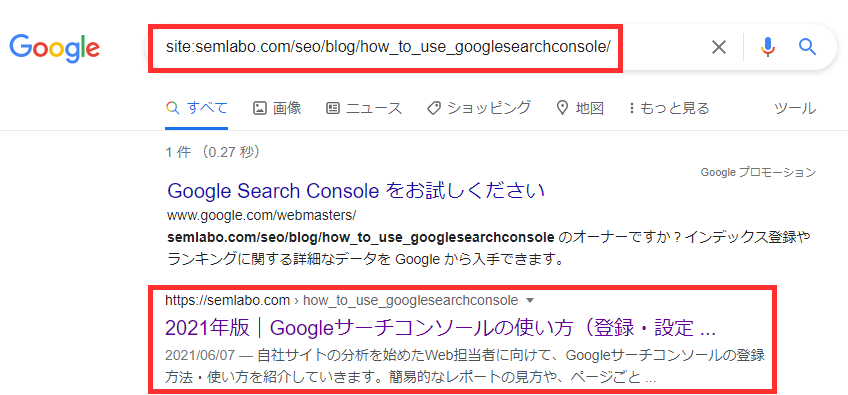
また、PC検索であれば、「ツール」からインデックスの期間を絞り込むことで、該当の期間内にインデックスされたページの件数を調べることもできます。
インデックスされていれば検索結果に表示されますが、あくまで簡易計測であることに注意しましょう。
Googleサーチコンソールで確認する
Googleサーチコンソールを使えば、ページがインデックスされているかどうか簡単に調べることができます。
手順は下記のとおりです。
- Search Consoleにログイン
- 画面上部の検索窓に調べたいURLをペースト
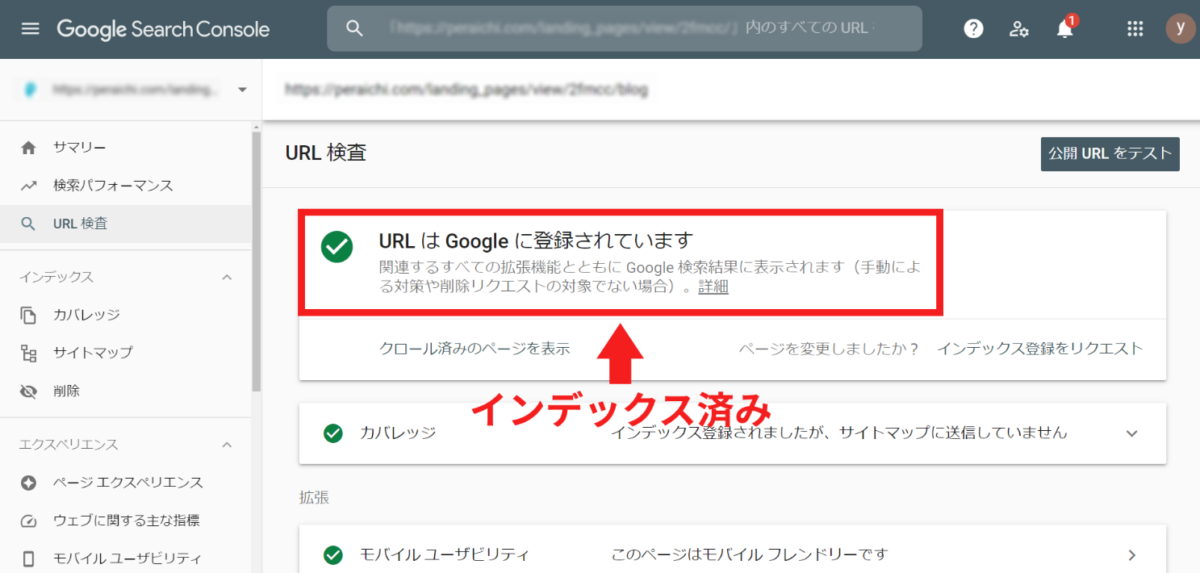
画像にように「URLはGoogleに登録されています」と表示されれば、インデックスされていることになります。
なお、「URLはGoogleに登録されていません」と表示されたら、インデックスを促すために「インデックスのリクエスト」を送信しましょう。
前述の「クロールリクエスト」の項目を参照してください。
また、「サイト全体について、クローラーがどれくらい訪れているか?」は、同じくサーチコンソールの「クロール統計情報」から確認できます。
左サイドメニューの「設定」画面を開くと「クロール統計情報」という項目がありますので、「レポートを開く」を押下して頻度やbotのクロール状況をチェックしてみましょう。
詳細画面を開けば、URL単位での確認も可能です。
クローラーに関するよくあるご質問
-
- クローリングを最適化するメリットはなんですか?
- 検索エンジンは、ページをクロールすることで初めてそのページの存在や内容を認識することができます。
クローリングの最適化を実施することで、新しく作成したページや更新したページが、検索エンジンにより伝わりやすくなることが期待できます。
-
- ページがなかなかクロールされない場合、どのような原因が考えられますか?
- サイト内において、該当ページへのリンクが適切に辿れる状態になっているか確認してください。
その際、リンクが<a>タグで記述されているかもチェックしましょう。
また、robots.txtやmetaタグでクロールが拒否されていないかも確認してください。
まとめ
クローラーの仕組みを理解することで、より効果的にWebサイトを構築できるだけでなく、SEOにおいてもよい影響が期待できます。
「コンテンツを追加しても効果が現れにくい」、「いつまでも検索結果に表示されない」といった課題のあるサイトは、クローラビリティに問題があるのかもしれません。
クローラーにWebページへの巡回をしてもらうためにいくつかの手法を紹介しましたので、取組中のSEOに成果が出ていない方はぜひ実践してみてください。
- SEO対策でビジネスを加速させる

-
SEO対策でこんな思い込みしていませんか?
- 大きいキーワードボリュームが取れないと売上が上がらない・・
- コンサルに頼んでもなかなか改善しない
- SEOはコンテンツさえ良ければ上がる
大事なのは自社にあったビジネス設計です。
御社の課題解決に直結するSEO施策をご提案します
 シェア
シェア




